This tutorial introduces the conceptual and theoretical foundations of Text Analysis (TA) — the computational extraction, processing, and interpretation of unstructured textual data. Due to the rapid growth of digitally available texts across every domain of human activity, methods for analysing large bodies of text computationally have become essential tools in linguistics, literary studies, history, communication research, social science, and beyond (Welbers, Van Atteveldt, and Benoit 2017; Jockers and Thalken 2020; Bernard and Ryan 1998; Kabanoff 1997; Popping 2000).
This is Part 1 of a two-part tutorial series. Part 1 focuses on concepts, terminology, and theoretical underpinnings — the what and why of text analysis. Part 2 focuses on the practical implementation of selected methods in R.
Prerequisite Tutorials
Before working through this tutorial, it is helpful to be familiar with:
What is Text Analysis? — definitions, scope, and related fields
The Text Analysis Landscape — TA, Corpus Linguistics, NLP, Text Mining, Distant Reading
The Text Analysis Pipeline — from raw data to insight
Core Concepts and Terminology — a structured glossary with depth
Data Sources for Text Analysis — corpora, web, archives
Epistemological and Ethical Considerations — what we can and cannot know
Tools versus Scripts — the case for reproducible, code-based research
Citation
Martin Schweinberger. 2026. Introduction to Text Analysis: Concepts and Foundations. The Language Technology and Data Analysis Laboratory (LADAL), The University of Queensland, Australia. url: https://ladal.edu.au/tutorials/introta/introta.html (Version 2026.03.27), doi: .
What Is Text Analysis?
Section Overview
What you’ll learn: How Text Analysis is defined, what distinguishes it from related fields, and why it is becoming central to humanities and social science research
Text Analysis (TA) refers to the process of examining, processing, and interpreting unstructured data — texts — to uncover patterns, relationships, and insights using computational methods. The texts in question can be extraordinarily diverse: emails, literary novels, historical letters, newspaper articles, social media posts, court transcripts, parliamentary debates, product reviews, academic papers, or any other written record of human language and thought.
The word unstructured is used to contrast textual data with structured (tabular) data, such as a spreadsheet where each column has a predefined meaning and data type. Texts do not arrive pre-organised into rows and columns; extracting structure from them is precisely the challenge that TA addresses.
Actionable knowledge — the goal of TA — refers to insights that can be used to classify documents, track trends, extract information, map relationships, test hypotheses, or support decision-making.
Text Analysis versus Text Analytics
The terms Text Analysis and Text Analytics are sometimes distinguished: Text Analysis is used for qualitative, interpretative, close-reading approaches, while Text Analytics refers to quantitative, computational approaches. In this tutorial series, we treat them as synonymous, encompassing any computer-assisted approach — qualitative or quantitative — to analysing text. The important distinction is not between the two labels, but between human-in-the-loop approaches (where computational methods assist human interpretation) and fully automated approaches (where algorithms process text with minimal human supervision).
Why Text Analysis Now?
The growth of interest in computational text analysis is not accidental — it reflects structural changes in how textual data is produced and stored:
Digitisation of existing records: Libraries, archives, and cultural institutions worldwide have digitised millions of historical documents, literary texts, newspapers, and government records, making them computationally accessible for the first time.
Born-digital text production: The internet has produced an unprecedented volume of natively digital text — social media, forums, news sites, emails, and more — which is already in a form amenable to computational analysis.
Methodological advances: Improvements in natural language processing, machine learning, and statistical methods have made it possible to extract meaningful information from text at scales previously unimaginable.
Computational accessibility: Tools and programming environments (including R and Python) have lowered the technical barrier to text analysis considerably. A researcher with modest programming skills can now perform analyses that previously required specialist expertise.
The Text Analysis Landscape
Section Overview
What you’ll learn: How Text Analysis relates to — and differs from — Corpus Linguistics, Natural Language Processing, Text Mining, and Distant Reading; and why understanding these distinctions matters for research design
Text Analysis (TA) is an umbrella term that encompasses several related fields and approaches. Understanding how these relate helps researchers choose the most appropriate framing and methods for their work.
Distant Reading
Distant Reading (DR) is an approach to analysing literary texts, pioneered by Franco Moretti (Moretti 2005, 2013). The central idea is that by analysing large corpora computationally — looking at statistical patterns across hundreds or thousands of texts — we can perceive literary and cultural trends that are invisible to any reader of individual texts. Distant reading explicitly positions itself as a complement to (not a replacement for) close reading, the traditional practice of interpreting individual texts in detail.
Moretti’s key provocation was that literature scholars could only ever closely read a small fraction of all published literature, and that this selection bias shapes what we think we know about literary history. Distant reading aims to correct this bias through systematic quantitative analysis. Representative applications include mapping genre evolution over centuries, tracking the rise and fall of specific narrative conventions, or analysing the representation of genders across thousands of novels.
Distant reading is sometimes used synonymously with Computational Literary Studies (CLS), which applies computational methods specifically to literary research questions.
Corpus Linguistics
Corpus Linguistics (CL) is a branch of linguistics that uses large, principled collections of authentic language data (corpora) to study language structure, use, variation, and change (Gries 2009; Stefanowitsch 2020; Amador Moreno 2010). CL is distinguished from armchair linguistics (constructing example sentences to illustrate grammatical points) by its commitment to empirical evidence drawn from actual language use.
Key features of corpus linguistics include:
Frequency-based reasoning: CL emphasises that what is common matters; grammatical and lexical choices that are frequent reveal what speakers actually do, not just what they can do
Probabilistic patterns: CL looks for tendencies and gradients, not categorical rules
Large-scale generalisation: findings about language are grounded in thousands or millions of examples, not individual judgements
Cross-corpus comparison: different corpora representing different varieties, genres, or time periods can be compared systematically
CL is generally more methodologically rigorous and statistically sophisticated than most TA work in the humanities — a heritage that comes from decades of developing and refining quantitative methods for language data.
Natural Language Processing
Natural Language Processing (NLP) is a field of computer science and artificial intelligence concerned with enabling computers to understand, interpret, and generate human language (Chowdhary and Chowdhary 2020; Eisenstein 2019; Indurkhya and Damerau 2010; Mitkov 2022). NLP is primarily technology development: its goal is to build systems and tools that process language automatically.
Key NLP applications include machine translation (Google Translate), speech recognition (Siri, Alexa), question answering (ChatGPT, search engines), information extraction, summarisation, and sentiment analysis. Modern NLP is dominated by large neural language models (transformer architectures such as BERT, GPT, and their successors), which are trained on enormous quantities of text and have achieved remarkable performance on many language tasks.
The relationship between NLP and TA is that of producer and consumer: NLP develops the tools (taggers, parsers, classifiers, embedding models) that TA researchers apply to their data. Many TA analyses rely on NLP-developed methods — part-of-speech tagging, named entity recognition, dependency parsing — without requiring expertise in the underlying machine learning.
Text Mining
Text Mining (TM) is a data science field focused on extracting information from large volumes of unstructured text using automated methods from NLP, machine learning, and statistics. Text Mining is decidedly data-driven and typically operates with minimal human supervision at scale. It is particularly associated with commercial applications — analysing customer reviews, social media monitoring, processing large document repositories — and with Big Data contexts where manual analysis is simply not feasible.
TM prioritises scalability and automation. The assumption is that the volume of data is so large that humans cannot be in the loop for individual documents; algorithms must classify, cluster, and extract information entirely automatically. This distinguishes TM from most TA and CL work, where human interpretation of results remains central.
How They Relate
Warning: package 'flextable' was built under R version 4.4.3
Field
Primary Domain
Data Types
Key Goal
Human in Loop?
Text Analysis (TA)
Humanities, social science
Any text
Understand texts and phenomena
Usually
Distant Reading (DR)
Literary / cultural studies
Literary corpora
Perceive literary/cultural patterns
Usually
Corpus Linguistics (CL)
Linguistics
Language corpora
Understand language use
Always
Natural Language Processing (NLP)
Computer science / AI
Any language data
Build language technology
Rarely (in production)
Text Mining (TM)
Data science / industry
Large-scale text (web, reviews)
Extract info at scale
Rarely
TA is broader than CL and DR — it is not limited to language study or literary texts, and it encompasses both qualitative and quantitative approaches. Compared to NLP, TA is more concerned with answering research questions than with building tools. Compared to TM, TA typically involves more interpretive engagement with individual texts and results.
Exercises: Definitions and Landscape
Q1. A researcher wants to study whether the way newspapers represent climate change has shifted between 2000 and 2020, using a collection of 50,000 articles. Which label best describes this work?
Q2. What is the key distinction between Text Mining and most Text Analysis work in the humanities?
The Text Analysis Pipeline
Section Overview
What you’ll learn: The typical sequence of steps from raw text to publishable finding, and the decisions that must be made at each stage
Why it matters: Treating text analysis as a linear pipeline makes it possible to identify where methodological choices have the greatest impact on results — and where errors are most likely to occur
Text analysis projects rarely proceed in a straight line, but it is useful to think in terms of a pipeline with distinct stages:
[1] Research Question
↓
[2] Data Collection and Corpus Construction
↓
[3] Pre-processing
↓
[4] Annotation (optional)
↓
[5] Analysis
↓
[6] Interpretation and Validation
↓
[7] Reporting and Sharing
Stage 1: Research Question
Every text analysis project should begin with a clearly formulated research question. Computational methods are tools in service of research questions; they should not be applied blindly to data in the hope that something interesting emerges. Good research questions are specific enough to be testable, open enough to allow surprising findings, and tied to a body of existing literature that contextualises what findings would mean.
Common types of TA research questions include:
Descriptive: What words, topics, or entities are most prominent in this corpus?
Comparative: How does the language used in text collection A differ from text collection B?
Diachronic: How has the representation of X changed over time?
Relational: What entities co-occur or are associated in this corpus?
Classificatory: Which documents belong to category A versus category B?
Stage 2: Data Collection and Corpus Construction
For most TA projects, the data is a corpus — a principled collection of texts assembled to address a specific research question. Corpus construction involves decisions about:
Representativeness: Does the corpus cover the phenomenon you want to study?
Balance: Are different varieties, genres, time periods, or authors proportionally represented?
Size: Is the corpus large enough to support statistical inferences? (A common misconception is that bigger is always better; a small but well-designed corpus often outperforms a large but poorly designed one.)
Sampling: How were texts selected? Is the selection principled and replicable?
Metadata: What contextual information about each text (author, date, genre, source) needs to be recorded?
Rights and licensing: Are the texts available for the intended use? (See the section on ethics below.)
Data can come from many sources: digitised book archives (Project Gutenberg, HathiTrust), news databases, social media APIs, government data portals, institutional repositories, or purpose-built linguistic corpora.
Stage 3: Pre-processing
Raw text is almost never in a form suitable for direct analysis. Pre-processing transforms raw text into a structured representation:
Encoding normalisation: Ensuring consistent character encoding (UTF-8 is standard)
Tokenisation: Splitting text into units (tokens) — words, sentences, or sub-word units
Lowercasing: Converting all text to lowercase to treat The and the as the same word
Punctuation and noise removal: Removing characters that are not relevant to the analysis
Stopword removal: Removing high-frequency function words (the, and, of) for frequency-based analyses where they would dominate
Normalisation: Stemming or lemmatisation to group inflected forms of the same word
Pre-processing decisions have a significant impact on results. Removing stopwords before a topic model, for example, will produce very different topics than keeping them. There are no universally correct choices — the right pre-processing depends on the research question and analysis method.
Stage 4: Annotation
Many analyses require adding linguistic or semantic information to the text. Annotation is the process of associating tags or labels with textual units:
Part-of-speech (PoS) tagging: labelling each token with its grammatical category (noun, verb, adjective…)
Named entity recognition (NER): identifying and categorising references to people, places, organisations, dates, and other real-world entities
Dependency parsing: labelling grammatical relationships between words (subject, object, modifier…)
Semantic tagging: assigning semantic category labels based on word meaning
Sentiment annotation: labelling text units with polarity (positive/negative) or emotion
Annotation can be manual (expensive, slow, high quality) or automatic (fast, scalable, error-prone). Most large-scale TA relies on automated annotation tools trained on manually annotated data.
Stage 5: Analysis
The analysis stage applies the methods described in the Glossary section below — frequency analysis, concordancing, collocation analysis, keyword analysis, topic modelling, sentiment analysis, and so on — to the pre-processed (and optionally annotated) text. Method choice should be driven by the research question, not by availability or familiarity.
Stage 6: Interpretation and Validation
Computational results require interpretation. A topic model produces lists of words; it does not produce topics with labels and meanings — that is the researcher’s job. A sentiment analysis produces polarity scores; it does not explain why texts have those scores. A keyword analysis produces statistically significant words; it does not explain what those words mean in context.
Validation — checking that results are meaningful and not artefacts of pre-processing or analytical choices — is often the most time-consuming and undervalued part of text analysis. Good practice includes inspecting samples of the data at each stage, checking whether different analytical choices produce consistent results (robustness checks), and comparing computational findings against expert judgement or existing knowledge.
Stage 7: Reporting and Sharing
Reproducibility is a core value of scientific research. For TA, this means sharing code, data (where licensing permits), and detailed descriptions of pre-processing and analytical choices so that other researchers can replicate, verify, and build upon findings. R Markdown and Quarto documents are ideal vehicles for this: they combine code, data, analysis, and narrative in a single reproducible document.
Exercises: The TA Pipeline
Q1. A researcher collects all tweets mentioning “climate change” from 2015–2023. Before analysis, they remove all non-English tweets, convert text to lowercase, and remove URLs and (mentions?). These steps belong to which pipeline stage?
Q2. Why is interpretation (stage 6) indispensable even when computational methods are fully automated?
Core Concepts and Terminology
Section Overview
What you’ll learn: The key concepts, units, and methods of text analysis — explained with sufficient depth to understand not just what they are but why they matter and when to use them
Words: Types, Tokens, and Lemmas
Understanding what counts as a “word” is the foundation of text analysis, and the answer is more nuanced than it first appears.
Consider the sentence: The cat sat on the mat.
One answer is that there are six words — six groups of characters separated by spaces and punctuation. These are tokens: individual instances of word forms in the text, counted with repetition. Tokens are the raw material of frequency analysis.
A different answer is five words — five distinct character sequences, one of which (the) appears twice. These are types: the unique vocabulary items in the text, counted without repetition. The ratio of types to tokens is the type-token ratio (TTR), a measure of lexical diversity. A higher TTR indicates more varied vocabulary.
A third consideration: are cat and cats the same word? They are distinct types, but intuitively they are variants of the same underlying word. This underlying form — the base form — is the lemma. In English, the lemma of running, ran, and runs is RUN. Lemmatisation is the process of mapping word forms to their lemmas, a common pre-processing step for analyses that should treat inflected variants as instances of the same word.
A related process is stemming, which truncates word forms to a common root using rule-based algorithms (e.g., running → run, runner → runner — but also university → univers). Stemming is faster than lemmatisation but less accurate; it does not consult a dictionary or consider semantic differences.
Concept
Definition
Example
Token
Individual word instance in text (counting with repetition)
'the' appears twice → 2 tokens
Type
Unique word form (counting without repetition)
6 tokens but 5 types in 'the cat sat on the mat'
Lemma
Base/dictionary form of a word
WALK is the lemma of walk, walks, walked, walking
Type-Token Ratio
Types ÷ Tokens — measure of lexical diversity
5 types / 6 tokens = 0.83 in the example sentence
Stem
Reduced root form produced by rule-based truncation
walk, walks, walked → 'walk' (via stemming)
Corpus (pl. Corpora)
A corpus is a machine-readable, electronically stored collection of natural language texts representing writing or speech, assembled according to explicit design criteria (Sinclair 1991). The design criteria — what texts to include, from whom, when, in what proportions — are what distinguish a corpus from a mere collection of texts.
Corpora serve as the empirical foundation of text analysis: they provide the data from which frequencies are computed, patterns extracted, and comparisons drawn. The quality of a corpus — its representativeness, balance, and documentation — directly determines the validity of analyses based on it.
There are four main types of corpora:
Monitor corpora are large, balanced collections representing a language or variety in its full breadth, continuously updated to track language change. Examples include the Corpus of Contemporary American English (COCA, 1 billion+ words) and the International Corpus of English (ICE). These are used for studying language use, testing linguistic hypotheses, and extracting authentic examples.
Learner corpora contain language produced by first or second language learners and are used to study acquisition, development, and learner-native speaker differences. Examples include the Child Language Data Exchange System (CHILDES) for L1 acquisition and the International Corpus of Learner English (ICLE) for L2 writing.
Historical or diachronic corpora contain texts from different time periods and enable the study of language change. Examples include the Penn Parsed Corpora of Historical English and The Helsinki Corpus of English Texts, both widely used in historical linguistics research.
Specialised corpora are narrow in scope, representing a specific genre, register, domain, or community. Examples include the British Academic Written English Corpus (BAWE) for academic writing and various specialised corpora of medical, legal, or scientific language.
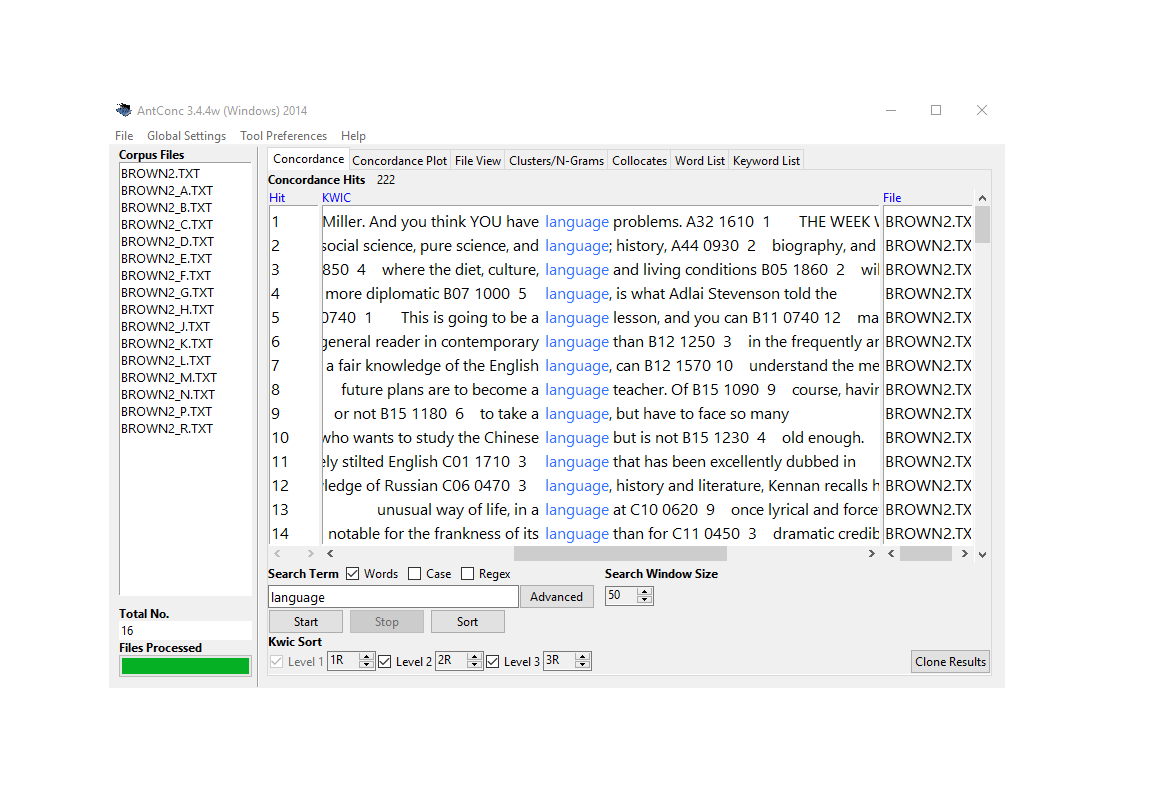
Concordancing
Concordancing is the extraction and display of all occurrences of a word or phrase in a text, each shown with its surrounding context (Lindquist 2009). The most common display format is the Key Word In Context (KWIC) display, in which the search term is centred with a window of preceding and following words on either side — typically five to ten words in each direction. Aligning all instances of the keyword vertically makes it easy to scan for patterns in the surrounding context at a glance.
Concordancing serves multiple purposes: inspecting how a term is used (disambiguation, pragmatic function), extracting authentic examples for illustration, identifying collocational patterns, and providing the qualitative evidence that quantitative frequency analysis cannot supply. It is often the first analytical step in a text analysis workflow — a sanity check before statistical analysis, and a source of examples to explain statistical results.
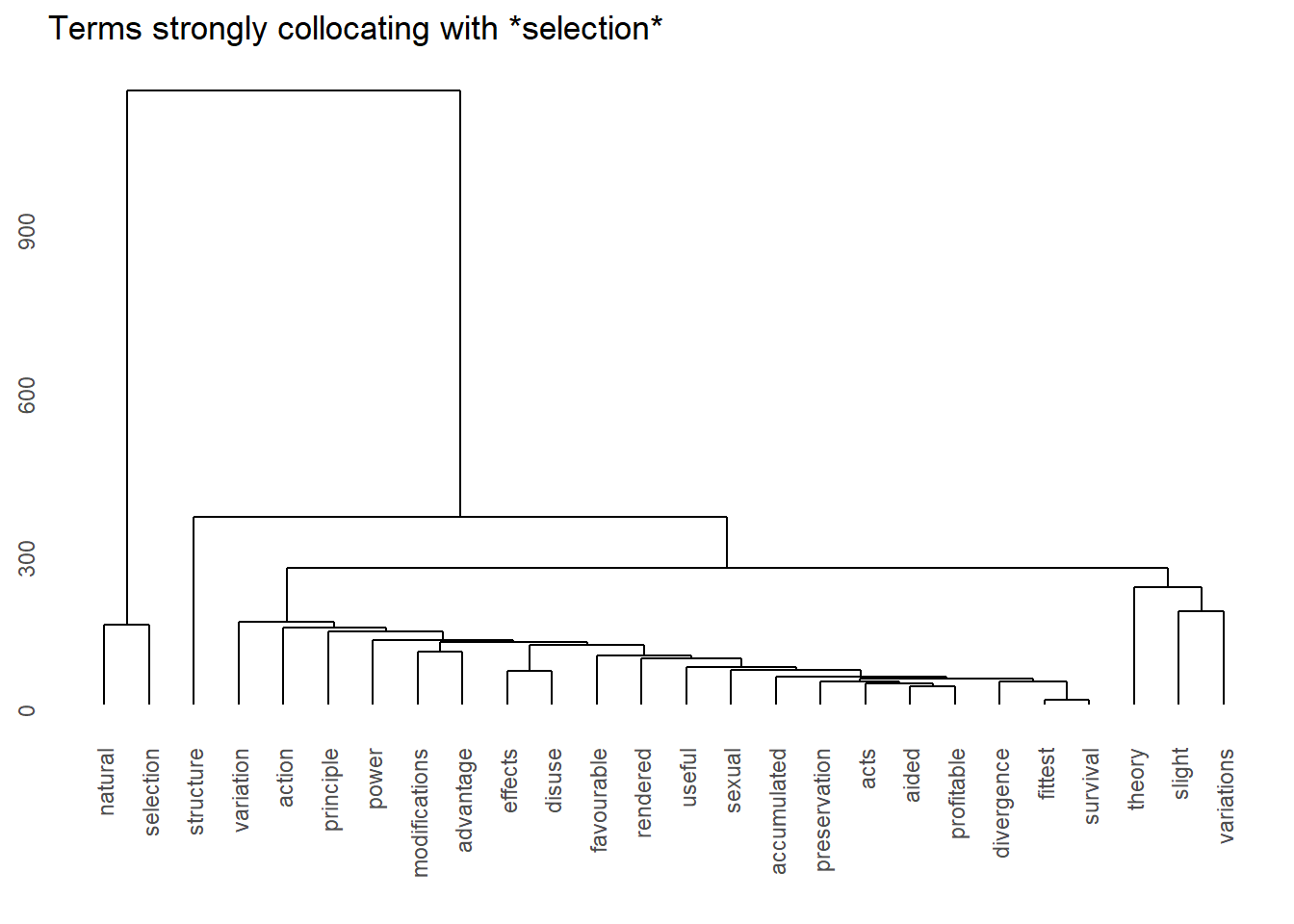
Collocations
Collocations are word pairs (or groups) that co-occur together more frequently than would be expected by chance, reflecting a genuine linguistic attraction between the words (Sinclair 1991; Evert et al. 2008). Classic English collocations include Merry Christmas (not Happy Christmas), strong tea (not powerful tea), and make a decision (not do a decision).
Collocations matter because they reveal the hidden patterning of language: every word has a characteristic set of collocates that defines its contextual behaviour, and these patterns are often invisible to introspection but emerge clearly from corpus data. They are central to lexicographic work, second-language teaching, and computational models of word meaning.
Collocation strength is measured by association measures derived from contingency tables — cross-tabulations of how often two words co-occur versus how often they occur independently. The most widely used measures are:
Mutual Information (MI): measures how much more often two words co-occur than expected by chance; sensitive to rare words
Log-likelihood (G²): a significance test for the co-occurrence; less sensitive to rare words than MI
phi (φ): an effect size measure derived from chi-square; captures the strength of the association
Delta P (ΔP): a directional measure that captures the asymmetric attraction between two words (how strongly does word A predict word B, and vice versa?)
Document-Term Matrix
A Document-Term Matrix (DTM) — also called a Term-Document Matrix (TDM) — is a mathematical representation of a collection of texts in which each row represents a document, each column represents a term (word), and each cell contains the frequency of that term in that document. The DTM is the central data structure for most quantitative text analysis methods: frequency analysis, keyword analysis, topic modelling, and text classification all operate on DTMs.
DTMs are typically very sparse: most words appear in only a small fraction of documents, so the matrix contains many zeros. This sparsity is both a computational challenge and an analytical opportunity — terms that are non-zero in a document are the ones that characterise it.
A key variant is the tf-idf weighted DTM (see below), in which raw frequencies are replaced by scores that reflect how characteristic each term is of each document relative to the collection as a whole.
Frequency Analysis
Frequency Analysis is the most fundamental text analysis method: counting how often words (or other units) occur in a text or corpus. Despite its simplicity, frequency analysis is enormously informative. The most frequent words in a text reveal its vocabulary profile; comparing frequency profiles across texts reveals vocabulary differences; tracking frequency changes over time reveals diachronic trends.
Raw frequency counts are often less useful than relative frequencies (counts per 1,000 or per million words), which make it possible to compare texts of different lengths. Frequency distributions in natural language follow Zipf’s Law: a small number of words (mostly function words) account for a large proportion of all tokens, while the vast majority of types occur very rarely. This heavily skewed distribution has significant implications for statistical analysis.
Keyword Analysis
Keyword Analysis identifies words that are statistically over-represented in one text or corpus (the target corpus) compared to another (the reference corpus). A keyword is not simply a frequent word — it is a word that is disproportionately frequent, whose elevated frequency cannot be explained by chance. Keywords characterise what makes one text or collection of texts different from another.
The concept of keyness is operationalised through various statistical measures, including log-likelihood, chi-square, and tf-idf (see below). The choice of reference corpus is critical: the same text can produce very different keywords depending on whether it is compared to a general language corpus, a genre-specific corpus, or another text in the same collection.
Term Frequency–Inverse Document Frequency (tf-idf)
tf-idf is a weighting scheme that reflects how characteristic a word is of a specific document within a collection. It combines two components:
Term frequency (tf): how often the word appears in the document (higher = more relevant to this document)
Inverse document frequency (idf): the inverse of how many documents contain the word (higher = rarer across the collection = more distinctive)
Words that are very common across all documents (like the, and, is) get a low tf-idf score even if they appear frequently in a document, because their presence does not distinguish the document from others. Words that appear frequently in one document but rarely in others get a high tf-idf score, marking them as characteristic of that document. Tf-idf is widely used in information retrieval (search engines) and as a feature weighting method for text classification.
N-Grams
N-grams are contiguous sequences of n tokens from a text. Unigrams are single words; bigrams are two-word sequences; trigrams are three-word sequences, and so on. The sentence I really like pizza contains the bigrams I really, really like, and like pizza, and the trigrams I really like and really like pizza.
N-gram analysis extends frequency analysis from single words to multi-word sequences, capturing phraseological patterns that word-level analysis misses. N-grams are foundational in language modelling (predicting the next word given the preceding n-1 words), in stylometry (authorship attribution), in collocation analysis, and in building phrase-level features for text classification.
Part-of-Speech Tagging
Part-of-Speech (PoS) Tagging is an annotation process that assigns grammatical category labels (noun, verb, adjective, adverb, preposition, etc.) to each token in a text. PoS tags enable grammatical filtering (extract all nouns; find all adjective-noun sequences), disambiguation (distinguish bank as a noun from bank as a verb), and more sophisticated analyses that take grammatical structure into account.
The most widely used tagset for English is the Penn Treebank tagset (45 tags), though the Universal Dependencies (UD) tagset (17 coarse tags) is increasingly standard for cross-linguistic work. Modern PoS taggers achieve accuracy above 97% on standard English text; accuracy drops on social media, historical texts, and other non-standard varieties.
Named Entity Recognition
Named Entity Recognition (NER) identifies and classifies references to real-world entities in text — people, organisations, locations, dates, monetary values, and other named items. NER is foundational for information extraction: automatically populating databases from text, building knowledge graphs, answering questions about specific entities, and mapping networks of relationships.
NER systems typically use sequence labelling models (CRF, neural networks) trained on annotated data. Performance is high for well-resourced languages and standard entity categories (person, location, organisation) but degrades on specialised domains, historical text, and languages with limited training data.
Dependency Parsing
Dependency Parsing is the analysis of grammatical structure in terms of binary relationships between tokens — a head word and a dependent word, connected by a labelled arc indicating the grammatical relationship (subject, object, modifier, etc.). The result is a dependency tree rooted at the main verb of each sentence.
Dependency structures are useful for extracting subject-verb-object triples (who does what to whom), identifying nominal modification patterns (what adjectives modify which nouns), and building structured representations of sentence meaning for downstream tasks. In conjunction with NER, dependency parsing enables the extraction of relational facts: [Amazon] acquired [MGM] for [8.45 billion dollars].
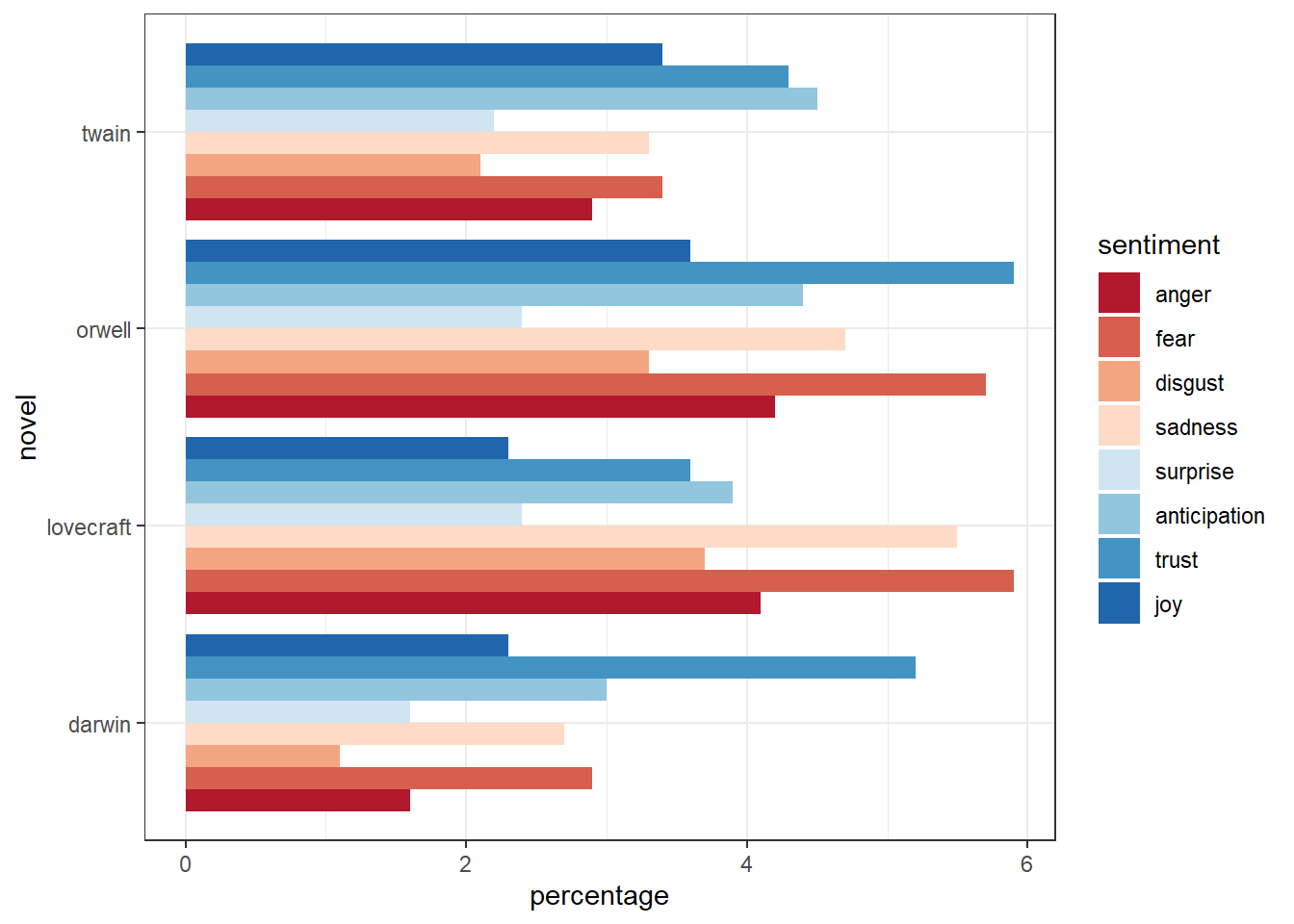
Sentiment Analysis
Sentiment Analysis is a suite of computational methods for determining the polarity (positive/negative) or emotional tone (joy, anger, fear, sadness, etc.) of a word, sentence, or text. Sentiment analysis is one of the most widely applied TA methods, particularly for analysing social media, product reviews, and customer feedback.
Two main approaches dominate:
Lexicon-based methods use dictionaries in which words are annotated with polarity or emotion labels. The sentiment of a text is computed by summing or averaging the scores of its words. Common lexicons include AFINN, BING, NRC, and SentiWordNet. Lexicon-based methods are transparent and require no training data, but they cannot handle irony, negation, or domain-specific language well.
Machine learning methods train a classifier on labelled examples (texts with known polarity). These methods can learn complex patterns including negation and domain-specific cues, but require labelled training data and are less transparent.
Semantic Analysis
Semantic Analysis encompasses methods that go beyond word form to analyse word meaning. Common approaches include:
Semantic field analysis: Grouping words by meaning category using annotated tagsets such as the UCREL Semantic Analysis System (USAS)
Word embeddings: Representing words as dense vectors in high-dimensional space (Word2Vec, GloVe, fastText) such that semantically similar words have similar vectors; enables computation of semantic similarity and analogy
Contextualised representations: Large language models (BERT, GPT) produce word representations that vary with context, capturing polysemy and nuance
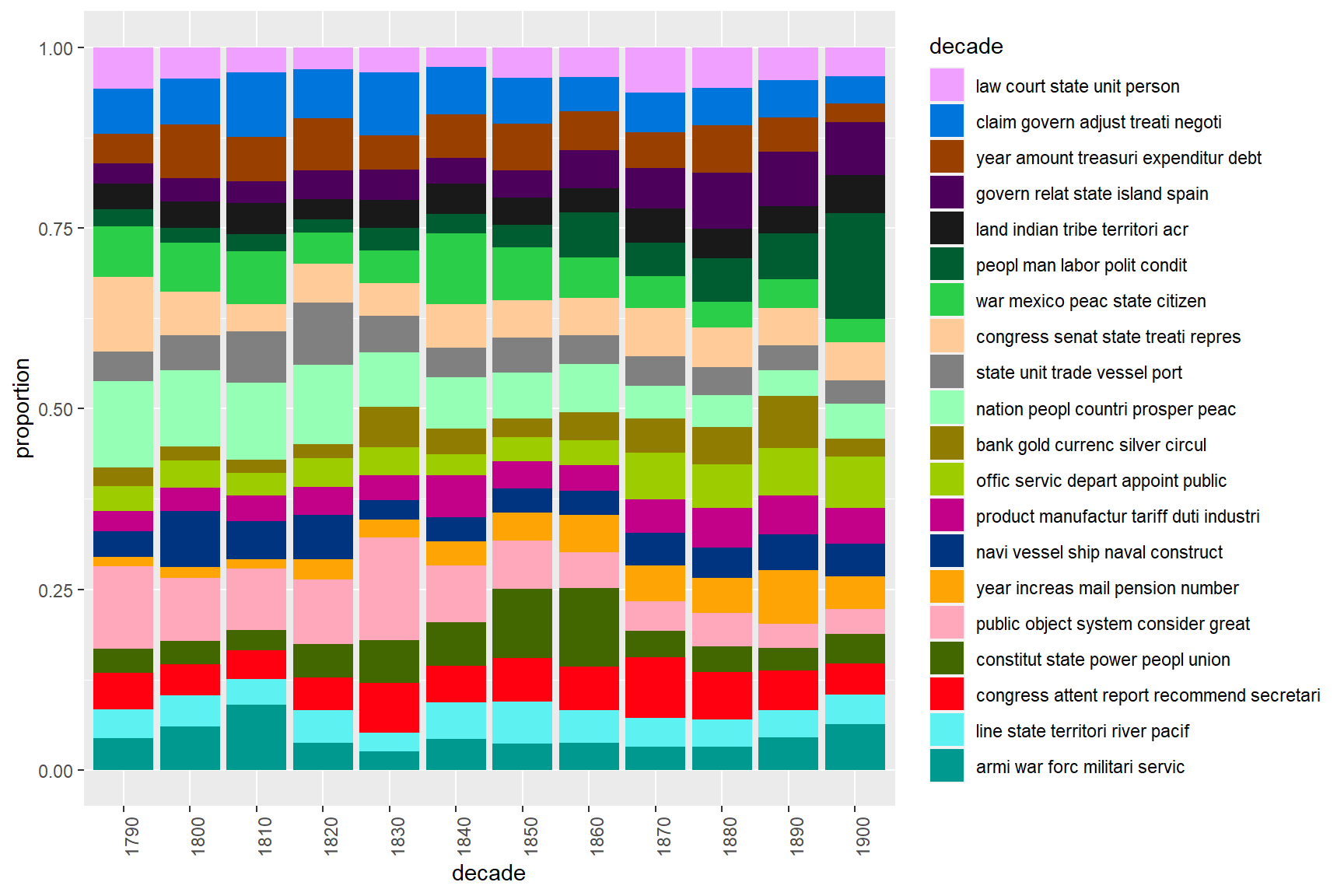
Topic Modelling
Topic Modelling is a family of unsupervised machine learning methods that discover latent thematic structure in a collection of documents by identifying groups of words that tend to co-occur (Blei, Ng, and Jordan 2003). The most widely used algorithm is Latent Dirichlet Allocation (LDA), which assumes that each document is a mixture of topics and each topic is a mixture of words, and estimates both simultaneously from the data.
The output of a topic model is a set of topics — each represented as a probability distribution over the vocabulary — and a set of document-topic distributions showing how much each topic contributes to each document. Interpreting topics requires human judgement: the researcher must examine the top words for each topic and decide what theme they represent.
Topic models are exploratory rather than confirmatory: they are most useful for generating hypotheses about the thematic structure of a corpus rather than for testing specific hypotheses. There are two main flavours:
Unsupervised (unseeded) topic models: The researcher specifies the number of topics k; the model finds k topics that best explain the corpus. The researcher must then interpret and label each topic.
Supervised (seeded) topic models: The researcher provides seed terms that anchor specific topics, guiding the model toward themes of interest. More appropriate when the researcher has specific thematic hypotheses.
Network Analysis
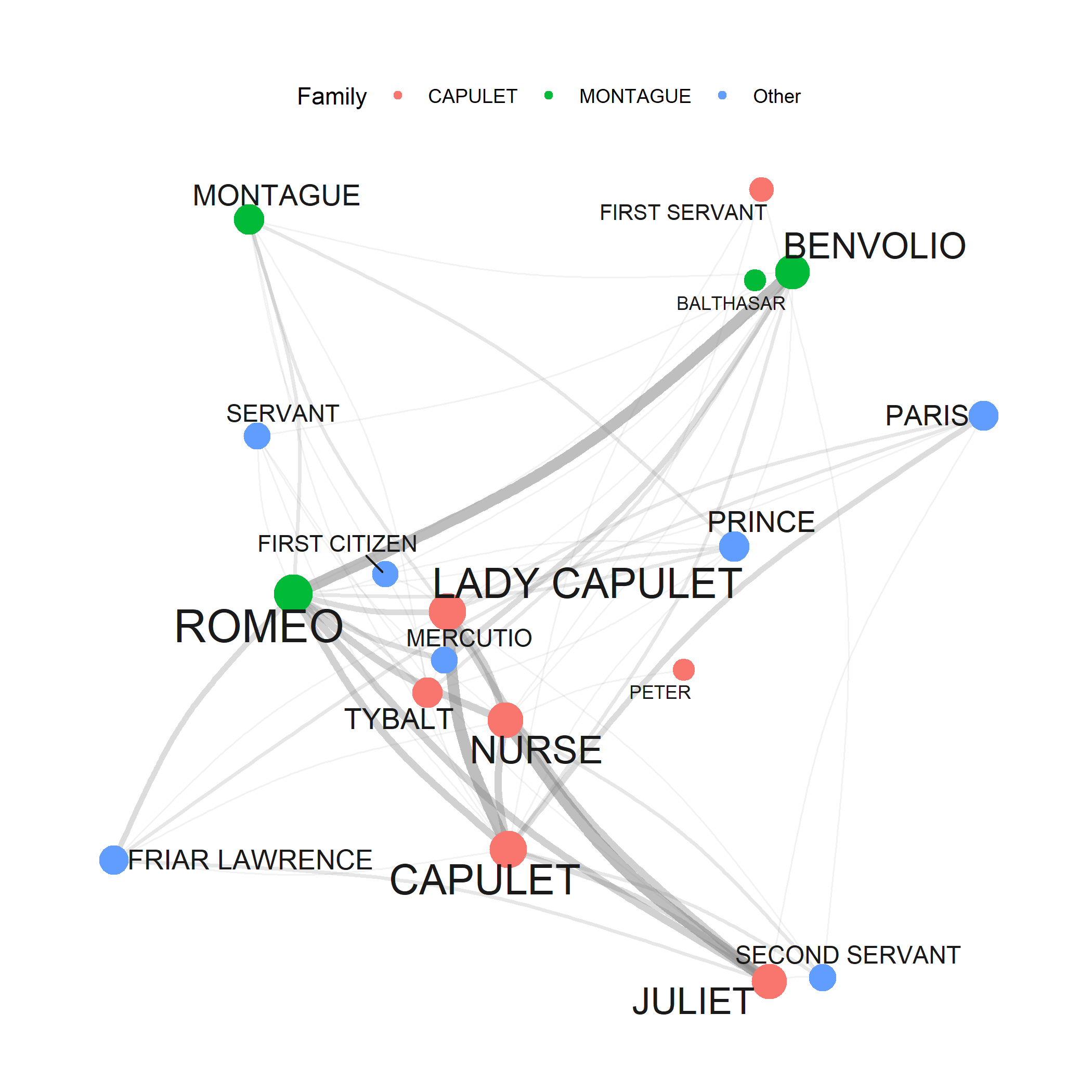
Network Analysis visualises and quantifies relationships between entities as graphs of nodes (entities) and edges (relationships). In text analysis, networks are used to represent co-occurrence relationships between words (collocation networks), interactions between characters in literary texts (character networks), citation relationships between academic papers, and communication networks derived from emails or social media.
Key network metrics include degree (how many connections a node has), betweenness centrality (how often a node lies on the shortest path between other nodes — a measure of broker/bridge status), and clustering coefficient (how interconnected a node’s neighbours are). Visualising networks reveals structural properties of relationships that tabular data cannot capture.
Regular Expressions
Regular expressions (regex) are patterns of characters used to search, match, and manipulate text. A regular expression like \b[Ww]alk\w*\b matches any word beginning with walk or Walk — walk, walks, walked, walking, walker, Walk, Walks, etc. — regardless of where in the text it appears.
Regular expressions are indispensable for text pre-processing (finding and replacing patterns), corpus searching (extracting examples matching complex criteria), and data cleaning. They are used in virtually every text analysis pipeline. A full introduction to regular expressions in R is available here.
Document Classification
Document Classification (also called text categorisation) is the process of assigning documents to predefined categories — genres, authors, languages, sentiment classes, topics, or any other labelling scheme. Classification can be:
Rule-based: Categories defined by explicit rules (e.g., documents containing the word invoice belong to the financial category)
Feature-based machine learning: Documents are represented as feature vectors (word frequencies, tf-idf weights, n-gram counts) and a classifier (logistic regression, SVM, random forest) is trained on labelled examples
Deep learning: Neural networks (LSTM, transformer models) that learn representations and classifications jointly from raw text
Applications include authorship attribution, genre classification, spam filtering, language identification, and sentiment classification.
Exercises: Core Concepts
Q1. A text contains 200 tokens but only 80 unique word forms. What is the type-token ratio, and what does it indicate?
Q2. What is the key conceptual difference between a COLLOCATION and a KEYWORD?
Q3. A topic model of 500 news articles produces 10 topics. Topic 3 has the top words: bank, loan, rate, interest, federal, mortgage, credit, reserve. What is the appropriate next step?
Data Sources for Text Analysis
Section Overview
What you’ll learn: Where to find text data for analysis, what to look for when evaluating a data source, and how to access key resources
Text data is available from an enormous variety of sources, but not all data is equally suitable for all research purposes. The key questions when evaluating a data source are: Who produced these texts? For what purpose? When? What selection biases might be present? And under what conditions is the data available?
Digitised Literary and Historical Archives
Project Gutenberg is the oldest digital library, containing over 60,000 ebooks in the public domain (free of US copyright). It is an excellent resource for literary, historical, and cultural text analysis. The gutenbergr R package provides direct access to the Project Gutenberg collection. A full tutorial on using gutenbergr is available here.
HathiTrust Digital Library contains over 17 million digitised volumes from major research libraries and is a major resource for large-scale literary and historical research.
Internet Archive provides access to billions of web pages via the Wayback Machine, as well as digitised books, films, music, and other media.
Linguistic Corpora
Purpose-built linguistic corpora are typically higher quality than opportunistically collected text data because they have explicit design criteria, metadata, and documentation. Major publicly accessible corpora include:
COCA (Corpus of Contemporary American English): 1 billion+ words, multiple genres, 1990–present
BNC (British National Corpus): 100 million words of late 20th-century British English
CHILDES: Child language acquisition data in dozens of languages
ICE (International Corpus of English): Comparable national varieties of English worldwide
SketchEngine: A corpus tool providing access to many large corpora
News and Social Media
News archives (e.g., LexisNexis, Factiva, ProQuest) provide access to newspaper and magazine articles, though typically behind paywalls. The GDELT Project offers open access to media monitoring data at massive scale.
Social media platforms (Twitter/X, Reddit, YouTube comments) have historically provided APIs for research access, though these have become significantly more restricted in recent years. Existing datasets curated under previous API conditions remain valuable resources.
Government and Institutional Data
Parliamentary debates (Hansard in the UK, Congressional Record in the US), court judgements, government reports, and policy documents are typically in the public domain and available for research. These provide valuable data for political, legal, and historical research.
Web Scraping
Web scraping — programmatically downloading and extracting text from websites — can provide access to text data not available through APIs or archives. Web scraping raises legal, ethical, and technical considerations: researchers should check robots.txt files, comply with terms of service, and avoid overloading servers. The rvest R package is the primary tool for web scraping in R.
Epistemological and Ethical Considerations
Section Overview
What you’ll learn: The limitations of computational text analysis, the epistemological claims it can and cannot support, and the ethical issues raised by working with text data
Why it matters: Understanding what text analysis cannot do is as important as understanding what it can do
What Text Analysis Can and Cannot Do
Text analysis is a powerful set of methods, but it is not a magic box that produces truth from data. Several limitations deserve explicit acknowledgement:
Texts are not behaviour: Most text data is not a random sample of linguistic behaviour — it is a selection shaped by who wrote, what they wrote about, who published it, and who preserved it. Literary corpora overrepresent canonical (and often Western, male, and elite) texts. Social media data overrepresents young, English-speaking, and technology-using populations. Historical corpora preserve official and literate production and lose oral, informal, and marginalised voices.
Frequencies are not meanings: The fact that a word is frequent, or that two words co-occur, or that a topic appears in a corpus, does not tell us what these patterns mean. Meaning is always contextual, cultural, and interpretive — and assigning it to computational outputs requires the same careful scholarly judgement as any other form of textual interpretation.
Models embody assumptions: Every text analysis method embeds assumptions about language, meaning, and text. A bag-of-words model assumes that word order does not matter. A topic model assumes that documents are mixtures of topics. A sentiment lexicon encodes one community’s judgements about word valence. When these assumptions do not match the data or the research question, results can be misleading.
Criticism of Digital Humanities: Text Analysis and computational literary studies have attracted criticism for producing results that are either “banal or, if interesting, not statistically robust” — findings that are either obvious or methodologically questionable. This criticism is not without merit: many early text analysis studies applied methods uncritically, without adequate statistical rigour or connection to theoretical frameworks. The field is maturing, and researchers coming from quantitative traditions (statistics, corpus linguistics) are increasingly contributing methodological rigour. But the obligation to evaluate whether computational findings are actually new, meaningful, and methodologically sound remains a live concern.
Ethical Considerations
Copyright and intellectual property: Most texts produced after the early 20th century are under copyright, which restricts how they can be copied, distributed, and used. Research use of copyright material is governed by fair use / fair dealing provisions in different jurisdictions, but these are not unlimited. Researchers should understand the licensing terms of any data source they use.
Privacy and informed consent: Texts produced in public contexts (newspaper articles, published books) are generally available for research. Texts produced in semi-public or private contexts — social media posts, forum contributions, emails — raise more complex questions. Individuals may not expect their words to be collected, analysed, and published, even if those words appeared in a publicly accessible space.
Bias and representation: As noted above, text corpora are never neutral or representative. Computational analyses can amplify existing biases in the data, producing findings that reflect the composition of the corpus rather than anything true about the phenomena of interest.
Dual use: Some text analysis methods — surveillance of online communication, automated profiling of individuals, large-scale opinion monitoring — can be used in ways that raise serious concerns about privacy, civil liberties, and the instrumentalisation of language research.
Tools versus Scripts: The Case for Reproducible Research
Section Overview
What you’ll learn: Why code-based, script-driven text analysis is preferable to point-and-click tools for research purposes
Key principle: Reproducibility is not just a technical nicety — it is a scientific and ethical obligation
It is entirely possible to perform many text analysis tasks using graphical tools like AntConc(Anthony 2024) or SketchEngine(Kilgarriff et al. 2014). These tools are user-friendly, powerful, and appropriate for many purposes. So why does LADAL recommend script-based analysis in R?
Reproducibility: When analysis is performed by clicking through a graphical interface, there is no automatic record of what was done. Replicating the analysis requires redoing every step manually. When analysis is performed in an R script, every step is recorded, can be rerun with one command, and can be shared with other researchers.
Transparency: Scripts make the full analytical workflow visible — every pre-processing decision, every parameter setting, every statistical test. Point-and-click tools often obscure these decisions, making it difficult for readers to evaluate the methodological choices.
Flexibility and power: Graphical tools implement a fixed set of analyses. R provides access to hundreds of packages covering the full range of text analysis methods, which can be combined in arbitrary ways to address novel research questions.
Scalability: Running the same analysis on 100 files in R takes the same code as running it on 1 file. Doing the same in a GUI requires 100 repetitions of the same manual steps.
No vendor lock-in: Commercial tools (SketchEngine, NVivo) can change their pricing, APIs, or feature sets. Open source R packages remain available indefinitely and can be archived along with data and analysis code to ensure long-term reproducibility.
Community and error correction: R is one of the most widely used languages for statistical computing globally. A large, active community means that errors in packages are typically discovered and corrected quickly, documentation is extensive, and help is readily available.
None of this means that GUI tools have no place in research. They are valuable for exploratory work, teaching, and contexts where reproducibility requirements are lower. But for published research that claims to support generalisable conclusions, script-based analysis is the appropriate standard.
Exercises: Epistemology and Tools
Q1. A researcher analyses 10,000 tweets from 2020 about the US presidential election and concludes that “American voters were more excited about Biden than Trump.” What is the most significant methodological problem with this conclusion?
Q2. A PhD student performs keyword analysis by clicking through a commercial text analysis tool, finds significant keywords, and writes up the results. A reviewer asks: ‘What stopword list did you use? How was the reference corpus constructed?’ Why can the student not easily answer these questions?
Resources and Further Reading
LADAL Tutorials
LADAL provides tutorials covering the practical implementation of all the methods described in this tutorial:
Key works for deeper engagement with Text Analysis theory and methods include Welbers, Van Atteveldt, and Benoit (2017), Jockers and Thalken (2020), Moretti (2013), Sinclair (1991), Eisenstein (2019), and Silge, Robinson, and Robinson (2017).
Citation & Session Info
Citation
Martin Schweinberger. 2026. Introduction to Text Analysis: Concepts and Foundations. The Language Technology and Data Analysis Laboratory (LADAL), The University of Queensland, Australia. url: https://ladal.edu.au/tutorials/introta/introta.html (Version 2026.03.27), doi: .
@manual{martinschweinberger2026introduction,
author = {Martin Schweinberger},
title = {Introduction to Text Analysis: Concepts and Foundations},
year = {2026},
note = {https://ladal.edu.au/tutorials/introta/introta.html},
organization = {The Language Technology and Data Analysis Laboratory (LADAL), The University of Queensland, Australia},
edition = {2026.03.27}
doi = {}
}
This tutorial was developed with the assistance of Claude (claude.ai), a large language model created by Anthropic. Claude was used to help draft the tutorial text, structure the instructional content, generate the R code examples, and write the checkdown quiz questions and feedback strings. All content was reviewed, edited, and approved by the author (Martin Schweinberger), who takes full responsibility for the accuracy and pedagogical appropriateness of the material. The use of AI assistance is disclosed here in the interest of transparency and in accordance with emerging best practices for AI-assisted academic content creation.
Amador Moreno, Carolina P. 2010. “How Can Corpora Be Used to Explore Literary Speech Representation?” In The Routledge Handbook of Corpus Linguistics, edited by Anne O’Keeffe and Michael McCarthy, 531–44. Abingdon (UK) & New York: Routeledge. https://doi.org/https://doi.org/10.4324/9780203856949-38.
Bernard, H Russell, and Gery Ryan. 1998. “Text Analysis.”Handbook of Methods in Cultural Anthropology 613.
Blei, David M., Andrew Y. Ng, and Michael I. Jordan. 2003. “Latent Dirichlet Allocation.”Journal of Machine Learning Research 3: 993–1022. https://doi.org/https://doi.org/10.5555/944919.944937.
Chowdhary, KR1442, and KR Chowdhary. 2020. “Natural Language Processing.”Fundamentals of Artificial Intelligence, 603–49.
Eisenstein, Jacob. 2019. Introduction to Natural Language Processing. MIT Press.
Evert, Stefan et al. 2008. “Corpora and Collocations.”Corpus Linguistics. An International Handbook 2: 1212–48.
Indurkhya, Nitin, and Fred J Damerau. 2010. Handbook of Natural Language Processing. 2nd edition. Routledge.
Jockers, Matthew L, and Rosamond Thalken. 2020. Text Analysis with r. Springer.
Kabanoff, Boris. 1997. “Introduction: Computers Can Read as Well as Count: Computer-Aided Text Analysis in Organizational Research.”Journal of Organizational Behavior, 507–11.
Kilgarriff, Adam, Vít Baisa, Jan Bušta, Miloš Jakubíček, Vojtěch Kovář, Jan Michelfeit, Pavel Rychlý, and Vít Suchomel. 2014. “The Sketch Engine: Ten Years On.”Lexicography 1: 7–36.
Lindquist, Hans. 2009. Corpus Linguistics and the Description of English. Vol. 104. Edinburgh: Edinburgh University Press.
Mitkov, Ruslan. 2022. The Oxford Handbook of Computational Linguistics. Oxford: Oxford University Press.
Moretti, Franco. 2005. Graphs, Maps, Trees: Abstract Models for a Literary History. Vol. 43. Verso. https://doi.org/https://doi.org/10.5860/choice.43-2646.
Silge, Julia, David Robinson, and David Robinson. 2017. Text Mining with r: A Tidy Approach. O’reilly Boston (MA).
Sinclair, John. 1991. Corpus, Concordance, Collocation. Describing English Language. Oxford: Oxford University Press.
Stefanowitsch, Anatol. 2020. Corpus Linguistics. A Guide to the Methodology. Textbooks in Language Sciences. Berlin: Language Science Press. https://doi.org/https://doi.org/10.5281/zenodo.3735822.
Welbers, Kasper, Wouter Van Atteveldt, and Kenneth Benoit. 2017. “Text Analysis in r.”Communication Methods and Measures 11 (4): 245–65. https://doi.org/https://doi.org/10.1080/19312458.2017.1387238.
Source Code
---title: "Introduction to Text Analysis: Concepts and Foundations"author: "Martin Schweinberger"date: "2026"params: title: "Introduction to Text Analysis: Concepts and Foundations" author: "Martin Schweinberger" year: "2026" version: "2026.03.27" url: "https://ladal.edu.au/tutorials/introta/introta.html" institution: "The Language Technology and Data Analysis Laboratory (LADAL), The University of Queensland, Australia" description: "This tutorial provides a conceptual introduction to text analytics, covering key terminology, the treatment of text as data, an overview of core methods, common research applications, and considerations for research design. It is aimed at researchers in linguistics, digital humanities, and the social sciences who are new to computational text analysis and want a theoretical foundation before undertaking practical tutorials." doi: "10.5281/zenodo.19332888"format: html: toc: true toc-depth: 4 code-fold: show code-tools: true theme: cosmo---```{r setup, echo=FALSE, message=FALSE, warning=FALSE} library(checkdown) options(stringsAsFactors = FALSE) ```{ width=100% } # Introduction {#intro} { width=15% style="float:right; padding:10px" } This tutorial introduces the conceptual and theoretical foundations of **Text Analysis** (TA) — the computational extraction, processing, and interpretation of unstructured textual data. Due to the rapid growth of digitally available texts across every domain of human activity, methods for analysing large bodies of text computationally have become essential tools in linguistics, literary studies, history, communication research, social science, and beyond [@welbers2017text; @jockers2020text; @bernard1998text; @kabanoff1997introduction; @popping2000computer]. This is **Part 1** of a two-part tutorial series. Part 1 focuses on concepts, terminology, and theoretical underpinnings — the *what* and *why* of text analysis. **Part 2** focuses on the practical implementation of selected methods in R. ::: {.callout-note} ## Prerequisite Tutorials Before working through this tutorial, it is helpful to be familiar with: - [Getting Started with R and RStudio](/tutorials/intror/intror.html)- [Loading, Saving, and Generating Data in R](/tutorials/load/load.html)::: ::: {.callout-tip} ## What This Tutorial Covers 1. **What is Text Analysis?** — definitions, scope, and related fields 2. **The Text Analysis Landscape** — TA, Corpus Linguistics, NLP, Text Mining, Distant Reading 3. **The Text Analysis Pipeline** — from raw data to insight 4. **Core Concepts and Terminology** — a structured glossary with depth 5. **Data Sources for Text Analysis** — corpora, web, archives 6. **Epistemological and Ethical Considerations** — what we can and cannot know 7. **Tools versus Scripts** — the case for reproducible, code-based research ::: ::: {.callout-note}## Citation```{r citation-callout-top, echo=FALSE, results='asis'}cat( params$author, ". ", params$year, ". *", params$title, "*. ", params$institution, ". ", "url: ", params$url, " ", "(Version ", params$version, "), ", "doi: ", params$doi, ".", sep = "")```:::# What Is Text Analysis? {#whatis} ::: {.callout-note} ## Section Overview **What you'll learn:** How Text Analysis is defined, what distinguishes it from related fields, and why it is becoming central to humanities and social science research ::: { width=35% style="float:right; padding:10px" } **Text Analysis** (TA) refers to the process of examining, processing, and interpreting unstructured data — texts — to uncover patterns, relationships, and insights using computational methods. The texts in question can be extraordinarily diverse: emails, literary novels, historical letters, newspaper articles, social media posts, court transcripts, parliamentary debates, product reviews, academic papers, or any other written record of human language and thought. The word *unstructured* is used to contrast textual data with *structured* (tabular) data, such as a spreadsheet where each column has a predefined meaning and data type. Texts do not arrive pre-organised into rows and columns; extracting structure from them is precisely the challenge that TA addresses. *Actionable knowledge* — the goal of TA — refers to insights that can be used to classify documents, track trends, extract information, map relationships, test hypotheses, or support decision-making. ::: {.callout-tip} ## Text Analysis versus Text Analytics The terms *Text Analysis* and *Text Analytics* are sometimes distinguished: Text Analysis is used for qualitative, interpretative, close-reading approaches, while Text Analytics refers to quantitative, computational approaches. In this tutorial series, we treat them as synonymous, encompassing any computer-assisted approach — qualitative or quantitative — to analysing text. The important distinction is not between the two labels, but between **human-in-the-loop** approaches (where computational methods assist human interpretation) and **fully automated** approaches (where algorithms process text with minimal human supervision). ::: ## Why Text Analysis Now? {-} The growth of interest in computational text analysis is not accidental — it reflects structural changes in how textual data is produced and stored: **Digitisation of existing records**: Libraries, archives, and cultural institutions worldwide have digitised millions of historical documents, literary texts, newspapers, and government records, making them computationally accessible for the first time. **Born-digital text production**: The internet has produced an unprecedented volume of natively digital text — social media, forums, news sites, emails, and more — which is already in a form amenable to computational analysis. **Methodological advances**: Improvements in natural language processing, machine learning, and statistical methods have made it possible to extract meaningful information from text at scales previously unimaginable. **Computational accessibility**: Tools and programming environments (including R and Python) have lowered the technical barrier to text analysis considerably. A researcher with modest programming skills can now perform analyses that previously required specialist expertise. --- # The Text Analysis Landscape {#landscape} ::: {.callout-note} ## Section Overview **What you'll learn:** How Text Analysis relates to — and differs from — Corpus Linguistics, Natural Language Processing, Text Mining, and Distant Reading; and why understanding these distinctions matters for research design ::: Text Analysis (TA) is an umbrella term that encompasses several related fields and approaches. Understanding how these relate helps researchers choose the most appropriate framing and methods for their work. ## Distant Reading {-} **Distant Reading** (DR) is an approach to analysing literary texts, pioneered by Franco Moretti [@moretti2005graphs; @moretti2013distant]. The central idea is that by analysing large corpora computationally — looking at statistical patterns across hundreds or thousands of texts — we can perceive literary and cultural trends that are invisible to any reader of individual texts. Distant reading explicitly positions itself as a complement to (not a replacement for) *close reading*, the traditional practice of interpreting individual texts in detail. Moretti's key provocation was that literature scholars could only ever closely read a small fraction of all published literature, and that this selection bias shapes what we think we know about literary history. Distant reading aims to correct this bias through systematic quantitative analysis. Representative applications include mapping genre evolution over centuries, tracking the rise and fall of specific narrative conventions, or analysing the representation of genders across thousands of novels. Distant reading is sometimes used synonymously with **Computational Literary Studies** (CLS), which applies computational methods specifically to literary research questions. ## Corpus Linguistics {-} **Corpus Linguistics** (CL) is a branch of linguistics that uses large, principled collections of authentic language data (corpora) to study language structure, use, variation, and change [@gries2009whatiscorpuslinguistics; @stafanowitsch2020corpus; @amador2010how]. CL is distinguished from armchair linguistics (constructing example sentences to illustrate grammatical points) by its commitment to empirical evidence drawn from actual language use. Key features of corpus linguistics include: - **Frequency-based reasoning**: CL emphasises that what is common matters; grammatical and lexical choices that are frequent reveal what speakers actually do, not just what they can do - **Probabilistic patterns**: CL looks for tendencies and gradients, not categorical rules - **Large-scale generalisation**: findings about language are grounded in thousands or millions of examples, not individual judgements - **Cross-corpus comparison**: different corpora representing different varieties, genres, or time periods can be compared systematically CL is generally more methodologically rigorous and statistically sophisticated than most TA work in the humanities — a heritage that comes from decades of developing and refining quantitative methods for language data. ## Natural Language Processing {-} **Natural Language Processing** (NLP) is a field of computer science and artificial intelligence concerned with enabling computers to understand, interpret, and generate human language [@chowdhary2020natural; @eisenstein2019introduction; @indurkhya2010handbook; @mitkov2022oxford]. NLP is primarily *technology development*: its goal is to build systems and tools that process language automatically. Key NLP applications include machine translation (Google Translate), speech recognition (Siri, Alexa), question answering (ChatGPT, search engines), information extraction, summarisation, and sentiment analysis. Modern NLP is dominated by large neural language models (transformer architectures such as BERT, GPT, and their successors), which are trained on enormous quantities of text and have achieved remarkable performance on many language tasks. The relationship between NLP and TA is that of producer and consumer: NLP develops the tools (taggers, parsers, classifiers, embedding models) that TA researchers apply to their data. Many TA analyses rely on NLP-developed methods — part-of-speech tagging, named entity recognition, dependency parsing — without requiring expertise in the underlying machine learning. ## Text Mining {-} **Text Mining** (TM) is a data science field focused on extracting information from large volumes of unstructured text using automated methods from NLP, machine learning, and statistics. Text Mining is decidedly data-driven and typically operates with minimal human supervision at scale. It is particularly associated with commercial applications — analysing customer reviews, social media monitoring, processing large document repositories — and with *Big Data* contexts where manual analysis is simply not feasible. TM prioritises scalability and automation. The assumption is that the volume of data is so large that humans cannot be in the loop for individual documents; algorithms must classify, cluster, and extract information entirely automatically. This distinguishes TM from most TA and CL work, where human interpretation of results remains central. ## How They Relate {-} ```{r landscape_table, echo=FALSE} library(flextable) data.frame( Field = c("Text Analysis (TA)", "Distant Reading (DR)", "Corpus Linguistics (CL)", "Natural Language Processing (NLP)", "Text Mining (TM)"), Primary_domain = c("Humanities, social science", "Literary / cultural studies", "Linguistics", "Computer science / AI", "Data science / industry"), Data_types = c("Any text", "Literary corpora", "Language corpora", "Any language data", "Large-scale text (web, reviews)"), Key_goal = c("Understand texts and phenomena", "Perceive literary/cultural patterns", "Understand language use", "Build language technology", "Extract info at scale"), Human_in_loop = c("Usually", "Usually", "Always", "Rarely (in production)", "Rarely"), stringsAsFactors = FALSE ) |> dplyr::rename("Primary Domain" = Primary_domain, "Data Types" = Data_types, "Key Goal" = Key_goal, "Human in Loop?" = Human_in_loop) |> flextable() |> flextable::set_table_properties(width = .99, layout = "autofit") |> flextable::theme_zebra() |> flextable::fontsize(size = 10) |> flextable::fontsize(size = 11, part = "header") |> flextable::align_text_col(align = "left") |> flextable::set_caption(caption = "Comparison of Text Analysis and related fields.") |> flextable::border_outer() ```TA is broader than CL and DR — it is not limited to language study or literary texts, and it encompasses both qualitative and quantitative approaches. Compared to NLP, TA is more concerned with answering research questions than with building tools. Compared to TM, TA typically involves more interpretive engagement with individual texts and results. --- ::: {.callout-tip} ## Exercises: Definitions and Landscape ::: **Q1. A researcher wants to study whether the way newspapers represent climate change has shifted between 2000 and 2020, using a collection of 50,000 articles. Which label best describes this work?** ```{r}#| echo: false #| label: "LAND_Q1" check_question("Text Analysis — it uses computational methods to study a social/political phenomenon in a large text collection, with human interpretation of results", options =c( "Text Analysis — it uses computational methods to study a social/political phenomenon in a large text collection, with human interpretation of results", "Natural Language Processing — because it involves processing large volumes of text automatically", "Corpus Linguistics — because it uses a collection of texts to study language", "Distant Reading — because the researcher cannot read all 50,000 articles closely" ), type ="radio", q_id ="LAND_Q1", random_answer_order =TRUE, button_label ="Check answer", right ="Correct! This is a typical Text Analysis project: a humanities/social science research question (representation of climate change), computational methods applied to a large corpus, and human interpretation of findings. While it shares features with Corpus Linguistics (large text collection) and could loosely be called Distant Reading (50,000 articles), TA is the most accurate umbrella term since the focus is a social phenomenon rather than language per se or literary patterns. NLP would be the label if the goal were to build a system for classifying articles automatically.", wrong ="Think about the research goal (understanding a social phenomenon), the researcher's involvement in interpreting results, and which label best captures this combination.") ```--- **Q2. What is the key distinction between Text Mining and most Text Analysis work in the humanities?** ```{r}#| echo: false #| label: "LAND_Q2" check_question("Text Mining operates with minimal human supervision at scale; TA typically retains human interpretation of both process and results", options =c( "Text Mining operates with minimal human supervision at scale; TA typically retains human interpretation of both process and results", "Text Mining uses Python; Text Analysis uses R", "Text Mining is only used in commercial contexts; TA is only academic", "Text Mining analyses structured data; TA analyses unstructured text" ), type ="radio", q_id ="LAND_Q2", random_answer_order =TRUE, button_label ="Check answer", right ="Correct! The defining distinction is the role of human interpretation. Text Mining prioritises fully automated, scalable pipelines that process millions of documents without human involvement in individual decisions. Text Analysis in humanities research typically retains a human in the loop — researchers design the analysis, inspect intermediate results, make interpretive decisions, and validate findings qualitatively. Both use computational methods on unstructured text; both occur in academic and commercial contexts; and both can be done in R or Python.", wrong ="The distinction is not about tools, domain, or data type. Think about how much human judgement is involved at different stages of the analysis.") ```--- # The Text Analysis Pipeline {#pipeline} ::: {.callout-note} ## Section Overview **What you'll learn:** The typical sequence of steps from raw text to publishable finding, and the decisions that must be made at each stage **Why it matters:** Treating text analysis as a linear pipeline makes it possible to identify where methodological choices have the greatest impact on results — and where errors are most likely to occur ::: Text analysis projects rarely proceed in a straight line, but it is useful to think in terms of a pipeline with distinct stages: ``` [1] Research Question ↓ [2] Data Collection and Corpus Construction ↓ [3] Pre-processing ↓ [4] Annotation (optional) ↓ [5] Analysis ↓ [6] Interpretation and Validation ↓ [7] Reporting and Sharing ```## Stage 1: Research Question {-} Every text analysis project should begin with a clearly formulated research question. Computational methods are tools in service of research questions; they should not be applied blindly to data in the hope that something interesting emerges. Good research questions are specific enough to be testable, open enough to allow surprising findings, and tied to a body of existing literature that contextualises what findings would mean. Common types of TA research questions include: - **Descriptive**: What words, topics, or entities are most prominent in this corpus? - **Comparative**: How does the language used in text collection A differ from text collection B? - **Diachronic**: How has the representation of X changed over time? - **Relational**: What entities co-occur or are associated in this corpus? - **Classificatory**: Which documents belong to category A versus category B? ## Stage 2: Data Collection and Corpus Construction {-} For most TA projects, the data is a **corpus** — a principled collection of texts assembled to address a specific research question. Corpus construction involves decisions about: - **Representativeness**: Does the corpus cover the phenomenon you want to study? - **Balance**: Are different varieties, genres, time periods, or authors proportionally represented? - **Size**: Is the corpus large enough to support statistical inferences? (A common misconception is that bigger is always better; a small but well-designed corpus often outperforms a large but poorly designed one.) - **Sampling**: How were texts selected? Is the selection principled and replicable? - **Metadata**: What contextual information about each text (author, date, genre, source) needs to be recorded? - **Rights and licensing**: Are the texts available for the intended use? (See the section on ethics below.) Data can come from many sources: digitised book archives (Project Gutenberg, HathiTrust), news databases, social media APIs, government data portals, institutional repositories, or purpose-built linguistic corpora. ## Stage 3: Pre-processing {-} Raw text is almost never in a form suitable for direct analysis. Pre-processing transforms raw text into a structured representation: - **Encoding normalisation**: Ensuring consistent character encoding (UTF-8 is standard) - **Tokenisation**: Splitting text into units (tokens) — words, sentences, or sub-word units - **Lowercasing**: Converting all text to lowercase to treat *The* and *the* as the same word - **Punctuation and noise removal**: Removing characters that are not relevant to the analysis - **Stopword removal**: Removing high-frequency function words (*the*, *and*, *of*) for frequency-based analyses where they would dominate - **Normalisation**: Stemming or lemmatisation to group inflected forms of the same word Pre-processing decisions have a significant impact on results. Removing stopwords before a topic model, for example, will produce very different topics than keeping them. There are no universally correct choices — the right pre-processing depends on the research question and analysis method. ## Stage 4: Annotation {-} Many analyses require adding linguistic or semantic information to the text. **Annotation** is the process of associating tags or labels with textual units: - **Part-of-speech (PoS) tagging**: labelling each token with its grammatical category (noun, verb, adjective…) - **Named entity recognition (NER)**: identifying and categorising references to people, places, organisations, dates, and other real-world entities - **Dependency parsing**: labelling grammatical relationships between words (subject, object, modifier…) - **Semantic tagging**: assigning semantic category labels based on word meaning - **Sentiment annotation**: labelling text units with polarity (positive/negative) or emotion Annotation can be manual (expensive, slow, high quality) or automatic (fast, scalable, error-prone). Most large-scale TA relies on automated annotation tools trained on manually annotated data. ## Stage 5: Analysis {-} The analysis stage applies the methods described in the Glossary section below — frequency analysis, concordancing, collocation analysis, keyword analysis, topic modelling, sentiment analysis, and so on — to the pre-processed (and optionally annotated) text. Method choice should be driven by the research question, not by availability or familiarity. ## Stage 6: Interpretation and Validation {-} Computational results require interpretation. A topic model produces lists of words; it does not produce topics with labels and meanings — that is the researcher's job. A sentiment analysis produces polarity scores; it does not explain *why* texts have those scores. A keyword analysis produces statistically significant words; it does not explain what those words *mean* in context. Validation — checking that results are meaningful and not artefacts of pre-processing or analytical choices — is often the most time-consuming and undervalued part of text analysis. Good practice includes inspecting samples of the data at each stage, checking whether different analytical choices produce consistent results (robustness checks), and comparing computational findings against expert judgement or existing knowledge. ## Stage 7: Reporting and Sharing {-} Reproducibility is a core value of scientific research. For TA, this means sharing code, data (where licensing permits), and detailed descriptions of pre-processing and analytical choices so that other researchers can replicate, verify, and build upon findings. R Markdown and Quarto documents are ideal vehicles for this: they combine code, data, analysis, and narrative in a single reproducible document. --- ::: {.callout-tip} ## Exercises: The TA Pipeline ::: **Q1. A researcher collects all tweets mentioning "climate change" from 2015–2023. Before analysis, they remove all non-English tweets, convert text to lowercase, and remove URLs and @mentions. These steps belong to which pipeline stage?** ```{r}#| echo: false #| label: "PIPE_Q1" check_question("Pre-processing — transforming raw text into a cleaner, more structured form suitable for analysis", options =c( "Pre-processing — transforming raw text into a cleaner, more structured form suitable for analysis", "Annotation — adding linguistic information to the text", "Corpus construction — deciding which texts to include", "Validation — checking that results are meaningful" ), type ="radio", q_id ="PIPE_Q1", random_answer_order =TRUE, button_label ="Check answer", right ="Correct! Removing non-English content, lowercasing, and removing URLs and @mentions are all pre-processing steps: they transform raw, noisy text into a cleaner representation without yet extracting or adding any information. The corpus construction stage (stage 2) was the decision to collect tweets about climate change at all. Annotation (stage 4) would involve adding part-of-speech tags or sentiment labels. Validation (stage 6) would involve checking whether the results make sense.", wrong ="These steps are about cleaning and normalising the raw text, not about selecting which texts to include, adding new information, or evaluating results.") ```--- **Q2. Why is interpretation (stage 6) indispensable even when computational methods are fully automated?** ```{r}#| echo: false #| label: "PIPE_Q2" check_question("Computational methods produce patterns (scores, clusters, word lists); they do not produce meaning. Assigning meaning to patterns is a human interpretive act that requires domain knowledge.", options =c( "Computational methods produce patterns (scores, clusters, word lists); they do not produce meaning. Assigning meaning to patterns is a human interpretive act that requires domain knowledge.", "Computational methods always contain programming errors that humans must correct", "Stage 6 is only necessary for qualitative research, not quantitative text analysis", "Interpretation is required only when the sample size is small" ), type ="radio", q_id ="PIPE_Q2", random_answer_order =TRUE, button_label ="Check answer", right ="Correct! A topic model does not produce topics — it produces lists of statistically co-occurring words. A researcher must decide whether those word lists represent coherent topics, what to name them, and what their co-occurrence means for the research question. A sentiment classifier does not explain why texts are positive or negative. Statistical significance does not mean substantive importance. The interpretive step — connecting computational outputs to research questions, domain knowledge, and theoretical frameworks — is irreducible and belongs uniquely to the human researcher.", wrong ="Think about what a sentiment score, a topic cluster, or a keyword list actually is. Does the algorithm know what those numbers or words mean in context?") ```--- # Core Concepts and Terminology {#glossary} ::: {.callout-note} ## Section Overview **What you'll learn:** The key concepts, units, and methods of text analysis — explained with sufficient depth to understand not just *what* they are but *why* they matter and *when* to use them ::: ## Words: Types, Tokens, and Lemmas {-} Understanding what counts as a "word" is the foundation of text analysis, and the answer is more nuanced than it first appears. Consider the sentence: *The cat sat on the mat.* One answer is that there are **six words** — six groups of characters separated by spaces and punctuation. These are **tokens**: individual instances of word forms in the text, counted with repetition. Tokens are the raw material of frequency analysis. A different answer is **five words** — five distinct character sequences, one of which (*the*) appears twice. These are **types**: the unique vocabulary items in the text, counted without repetition. The ratio of types to tokens is the **type-token ratio** (TTR), a measure of lexical diversity. A higher TTR indicates more varied vocabulary. A third consideration: are *cat* and *cats* the same word? They are distinct types, but intuitively they are variants of the same underlying word. This underlying form — the base form — is the **lemma**. In English, the lemma of *running*, *ran*, and *runs* is *RUN*. **Lemmatisation** is the process of mapping word forms to their lemmas, a common pre-processing step for analyses that should treat inflected variants as instances of the same word. A related process is **stemming**, which truncates word forms to a common root using rule-based algorithms (e.g., *running* → *run*, *runner* → *runner* — but also *university* → *univers*). Stemming is faster than lemmatisation but less accurate; it does not consult a dictionary or consider semantic differences. ```{r word_table, echo=FALSE} data.frame( Concept = c("Token", "Type", "Lemma", "Type-Token Ratio", "Stem"), Definition = c("Individual word instance in text (counting with repetition)", "Unique word form (counting without repetition)", "Base/dictionary form of a word", "Types ÷ Tokens — measure of lexical diversity", "Reduced root form produced by rule-based truncation"), Example = c("'the' appears twice → 2 tokens", "6 tokens but 5 types in 'the cat sat on the mat'", "WALK is the lemma of walk, walks, walked, walking", "5 types / 6 tokens = 0.83 in the example sentence", "walk, walks, walked → 'walk' (via stemming)") ) |> flextable() |> flextable::set_table_properties(width = .99, layout = "autofit") |> flextable::theme_zebra() |> flextable::fontsize(size = 11) |> flextable::fontsize(size = 11, part = "header") |> flextable::align_text_col(align = "left") |> flextable::set_caption(caption = "Core word-level concepts in text analysis.") |> flextable::border_outer() ```## Corpus (pl. Corpora) {-} A **corpus** is a machine-readable, electronically stored collection of natural language texts representing writing or speech, assembled according to explicit design criteria [@sinclair1991corpus]. The design criteria — what texts to include, from whom, when, in what proportions — are what distinguish a corpus from a mere collection of texts. Corpora serve as the empirical foundation of text analysis: they provide the data from which frequencies are computed, patterns extracted, and comparisons drawn. The quality of a corpus — its representativeness, balance, and documentation — directly determines the validity of analyses based on it. There are four main types of corpora: **Monitor corpora** are large, balanced collections representing a language or variety in its full breadth, continuously updated to track language change. Examples include the *Corpus of Contemporary American English* (COCA, 1 billion+ words) and the *International Corpus of English* (ICE). These are used for studying language use, testing linguistic hypotheses, and extracting authentic examples. **Learner corpora** contain language produced by first or second language learners and are used to study acquisition, development, and learner-native speaker differences. Examples include the *Child Language Data Exchange System* (CHILDES) for L1 acquisition and the *International Corpus of Learner English* (ICLE) for L2 writing. **Historical or diachronic corpora** contain texts from different time periods and enable the study of language change. Examples include the *Penn Parsed Corpora of Historical English* and *The Helsinki Corpus of English Texts*, both widely used in historical linguistics research. **Specialised corpora** are narrow in scope, representing a specific genre, register, domain, or community. Examples include the *British Academic Written English Corpus* (BAWE) for academic writing and various specialised corpora of medical, legal, or scientific language. ## Concordancing {-} 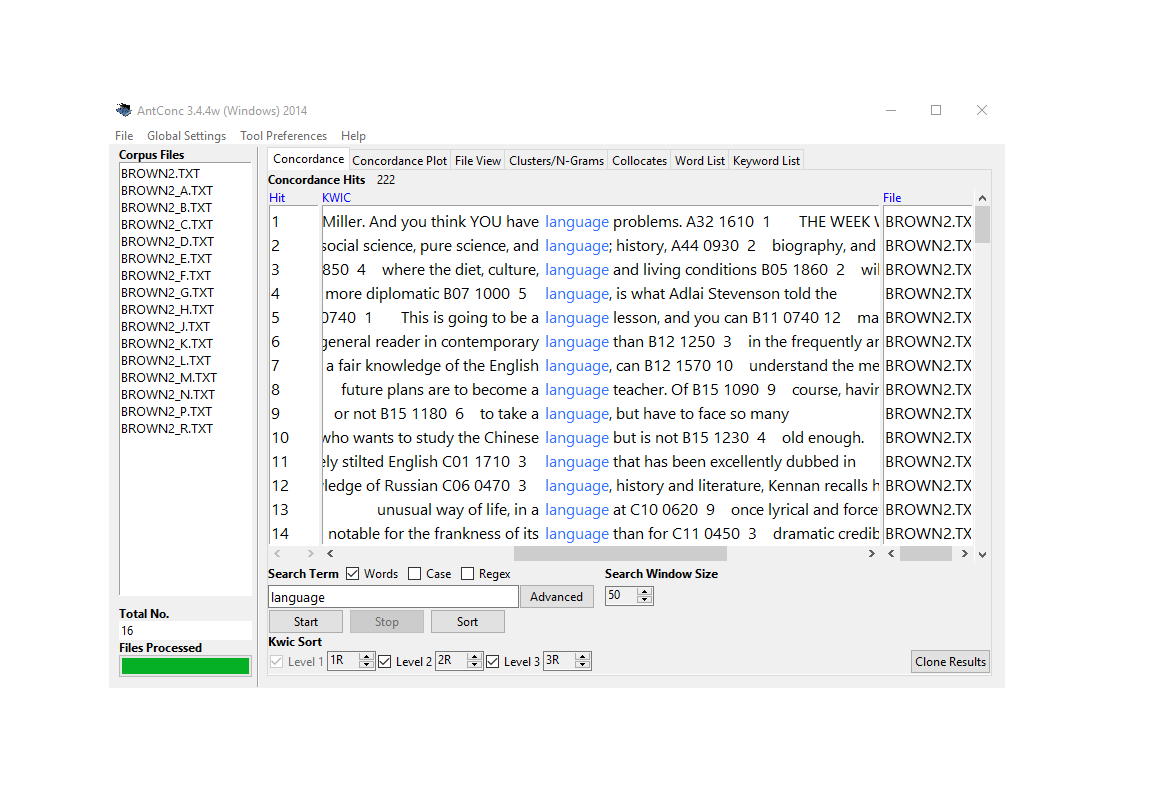{ width=40% style="float:right; padding:10px" } **Concordancing** is the extraction and display of all occurrences of a word or phrase in a text, each shown with its surrounding context [@lindquist2009corpus]. The most common display format is the **Key Word In Context** (KWIC) display, in which the search term is centred with a window of preceding and following words on either side — typically five to ten words in each direction. Aligning all instances of the keyword vertically makes it easy to scan for patterns in the surrounding context at a glance. Concordancing serves multiple purposes: inspecting how a term is used (disambiguation, pragmatic function), extracting authentic examples for illustration, identifying collocational patterns, and providing the qualitative evidence that quantitative frequency analysis cannot supply. It is often the first analytical step in a text analysis workflow — a sanity check before statistical analysis, and a source of examples to explain statistical results. ## Collocations {-} 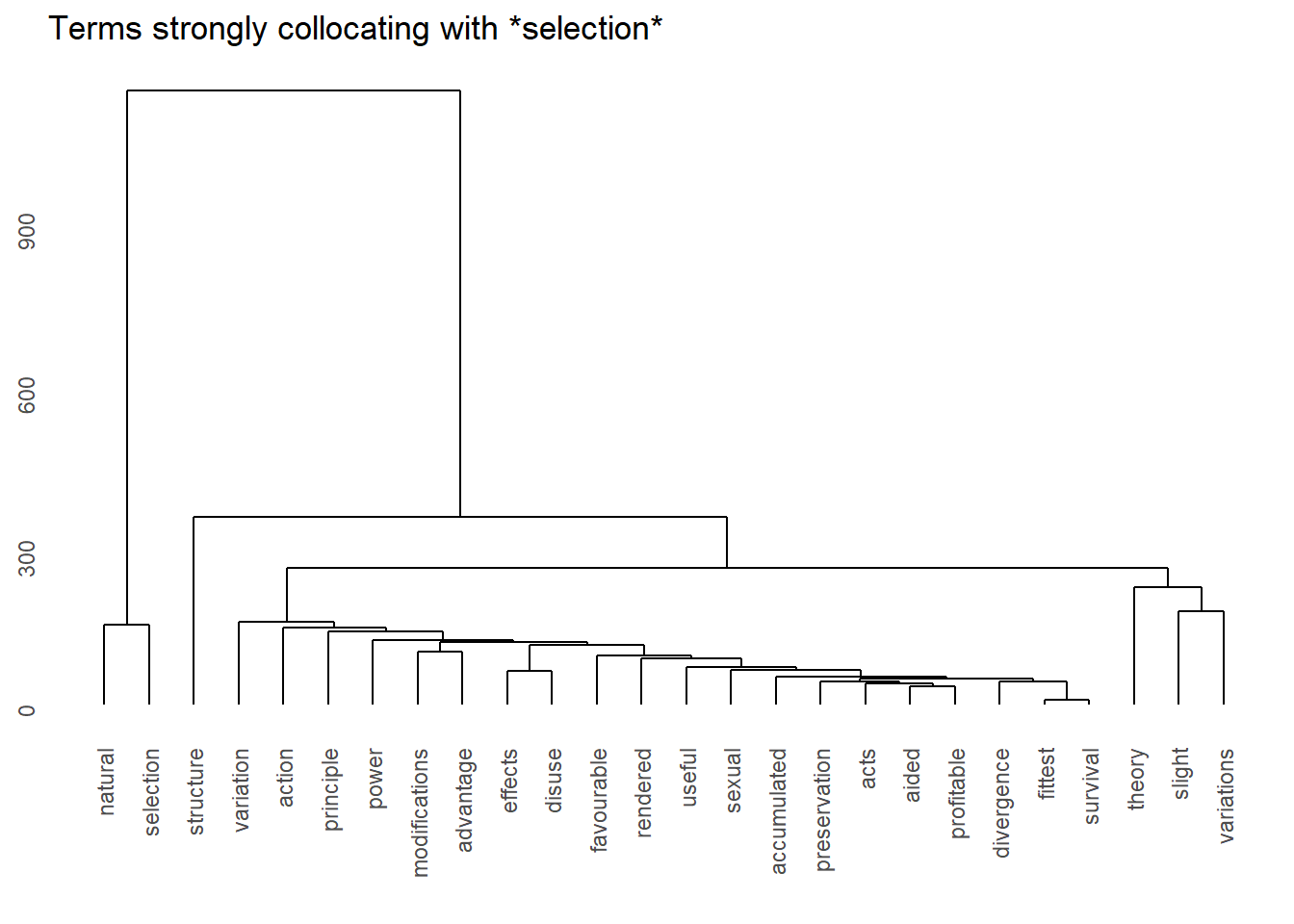{ width=40% style="float:right; padding:10px" } **Collocations** are word pairs (or groups) that co-occur together more frequently than would be expected by chance, reflecting a genuine linguistic attraction between the words [@sinclair1991corpus; @evert2008corpora]. Classic English collocations include *Merry Christmas* (not *Happy Christmas*), *strong tea* (not *powerful tea*), and *make a decision* (not *do a decision*). Collocations matter because they reveal the hidden patterning of language: every word has a characteristic set of collocates that defines its contextual behaviour, and these patterns are often invisible to introspection but emerge clearly from corpus data. They are central to lexicographic work, second-language teaching, and computational models of word meaning. Collocation strength is measured by **association measures** derived from contingency tables — cross-tabulations of how often two words co-occur versus how often they occur independently. The most widely used measures are: - **Mutual Information (MI)**: measures how much more often two words co-occur than expected by chance; sensitive to rare words - **Log-likelihood (G²)**: a significance test for the co-occurrence; less sensitive to rare words than MI - **phi (φ)**: an effect size measure derived from chi-square; captures the strength of the association - **Delta P (ΔP)**: a directional measure that captures the asymmetric attraction between two words (how strongly does word A predict word B, and vice versa?) ## Document-Term Matrix {-} A **Document-Term Matrix** (DTM) — also called a Term-Document Matrix (TDM) — is a mathematical representation of a collection of texts in which each row represents a document, each column represents a term (word), and each cell contains the frequency of that term in that document. The DTM is the central data structure for most quantitative text analysis methods: frequency analysis, keyword analysis, topic modelling, and text classification all operate on DTMs. DTMs are typically very **sparse**: most words appear in only a small fraction of documents, so the matrix contains many zeros. This sparsity is both a computational challenge and an analytical opportunity — terms that are non-zero in a document are the ones that characterise it. A key variant is the **tf-idf weighted** DTM (see below), in which raw frequencies are replaced by scores that reflect how characteristic each term is of each document relative to the collection as a whole. ## Frequency Analysis {-} **Frequency Analysis** is the most fundamental text analysis method: counting how often words (or other units) occur in a text or corpus. Despite its simplicity, frequency analysis is enormously informative. The most frequent words in a text reveal its vocabulary profile; comparing frequency profiles across texts reveals vocabulary differences; tracking frequency changes over time reveals diachronic trends. Raw frequency counts are often less useful than **relative frequencies** (counts per 1,000 or per million words), which make it possible to compare texts of different lengths. Frequency distributions in natural language follow **Zipf's Law**: a small number of words (mostly function words) account for a large proportion of all tokens, while the vast majority of types occur very rarely. This heavily skewed distribution has significant implications for statistical analysis. ## Keyword Analysis {-} **Keyword Analysis** identifies words that are statistically over-represented in one text or corpus (the *target corpus*) compared to another (the *reference corpus*). A keyword is not simply a frequent word — it is a word that is disproportionately frequent, whose elevated frequency cannot be explained by chance. Keywords characterise what makes one text or collection of texts different from another. The concept of keyness is operationalised through various statistical measures, including log-likelihood, chi-square, and tf-idf (see below). The choice of reference corpus is critical: the same text can produce very different keywords depending on whether it is compared to a general language corpus, a genre-specific corpus, or another text in the same collection. ## Term Frequency–Inverse Document Frequency (tf-idf) {-} **tf-idf** is a weighting scheme that reflects how characteristic a word is of a specific document within a collection. It combines two components: - **Term frequency (tf)**: how often the word appears in the document (higher = more relevant to this document) - **Inverse document frequency (idf)**: the inverse of how many documents contain the word (higher = rarer across the collection = more distinctive) Words that are very common across all documents (like *the*, *and*, *is*) get a low tf-idf score even if they appear frequently in a document, because their presence does not distinguish the document from others. Words that appear frequently in one document but rarely in others get a high tf-idf score, marking them as characteristic of that document. Tf-idf is widely used in information retrieval (search engines) and as a feature weighting method for text classification. ## N-Grams {-} **N-grams** are contiguous sequences of *n* tokens from a text. Unigrams are single words; bigrams are two-word sequences; trigrams are three-word sequences, and so on. The sentence *I really like pizza* contains the bigrams *I really*, *really like*, and *like pizza*, and the trigrams *I really like* and *really like pizza*. N-gram analysis extends frequency analysis from single words to multi-word sequences, capturing phraseological patterns that word-level analysis misses. N-grams are foundational in language modelling (predicting the next word given the preceding *n-1* words), in stylometry (authorship attribution), in collocation analysis, and in building phrase-level features for text classification. ## Part-of-Speech Tagging {-} **Part-of-Speech (PoS) Tagging** is an annotation process that assigns grammatical category labels (noun, verb, adjective, adverb, preposition, etc.) to each token in a text. PoS tags enable grammatical filtering (extract all nouns; find all adjective-noun sequences), disambiguation (distinguish *bank* as a noun from *bank* as a verb), and more sophisticated analyses that take grammatical structure into account. The most widely used tagset for English is the Penn Treebank tagset (45 tags), though the Universal Dependencies (UD) tagset (17 coarse tags) is increasingly standard for cross-linguistic work. Modern PoS taggers achieve accuracy above 97% on standard English text; accuracy drops on social media, historical texts, and other non-standard varieties. ## Named Entity Recognition {-} **Named Entity Recognition** (NER) identifies and classifies references to real-world entities in text — people, organisations, locations, dates, monetary values, and other named items. NER is foundational for information extraction: automatically populating databases from text, building knowledge graphs, answering questions about specific entities, and mapping networks of relationships. NER systems typically use sequence labelling models (CRF, neural networks) trained on annotated data. Performance is high for well-resourced languages and standard entity categories (person, location, organisation) but degrades on specialised domains, historical text, and languages with limited training data. ## Dependency Parsing {-} **Dependency Parsing** is the analysis of grammatical structure in terms of binary relationships between tokens — a head word and a dependent word, connected by a labelled arc indicating the grammatical relationship (subject, object, modifier, etc.). The result is a dependency tree rooted at the main verb of each sentence. Dependency structures are useful for extracting subject-verb-object triples (who does what to whom), identifying nominal modification patterns (what adjectives modify which nouns), and building structured representations of sentence meaning for downstream tasks. In conjunction with NER, dependency parsing enables the extraction of relational facts: *[Amazon] acquired [MGM] for [8.45 billion dollars]*. ## Sentiment Analysis {-} 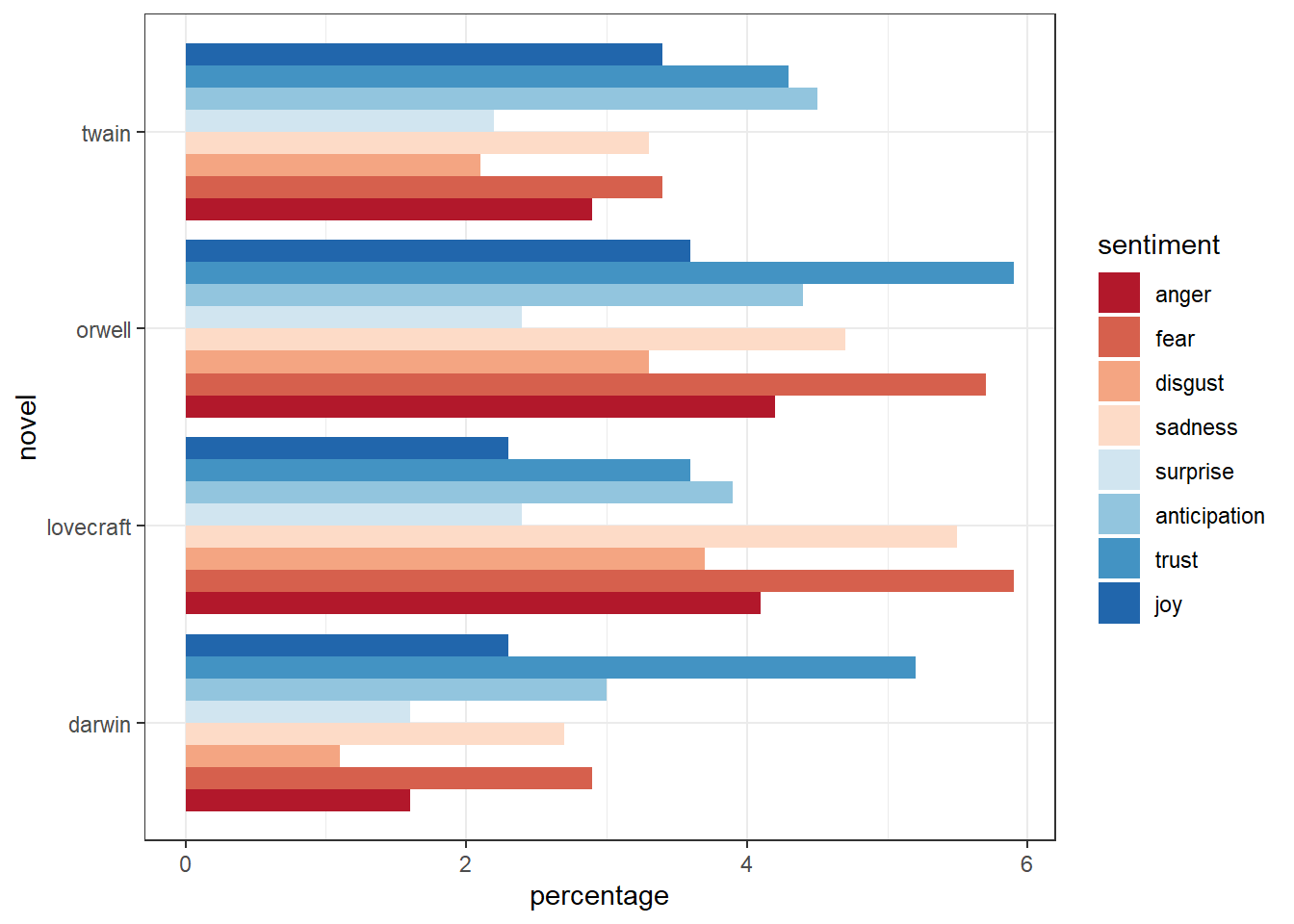{ width=35% style="float:right; padding:10px" } **Sentiment Analysis** is a suite of computational methods for determining the polarity (positive/negative) or emotional tone (joy, anger, fear, sadness, etc.) of a word, sentence, or text. Sentiment analysis is one of the most widely applied TA methods, particularly for analysing social media, product reviews, and customer feedback. Two main approaches dominate: **Lexicon-based methods** use dictionaries in which words are annotated with polarity or emotion labels. The sentiment of a text is computed by summing or averaging the scores of its words. Common lexicons include AFINN, BING, NRC, and SentiWordNet. Lexicon-based methods are transparent and require no training data, but they cannot handle irony, negation, or domain-specific language well. **Machine learning methods** train a classifier on labelled examples (texts with known polarity). These methods can learn complex patterns including negation and domain-specific cues, but require labelled training data and are less transparent. ## Semantic Analysis {-} **Semantic Analysis** encompasses methods that go beyond word form to analyse word *meaning*. Common approaches include: - **Semantic field analysis**: Grouping words by meaning category using annotated tagsets such as the UCREL Semantic Analysis System (USAS) - **Word embeddings**: Representing words as dense vectors in high-dimensional space (Word2Vec, GloVe, fastText) such that semantically similar words have similar vectors; enables computation of semantic similarity and analogy - **Contextualised representations**: Large language models (BERT, GPT) produce word representations that vary with context, capturing polysemy and nuance ## Topic Modelling {-} { width=35% style="float:right; padding:10px" } **Topic Modelling** is a family of unsupervised machine learning methods that discover latent thematic structure in a collection of documents by identifying groups of words that tend to co-occur [@blei2003latent]. The most widely used algorithm is **Latent Dirichlet Allocation** (LDA), which assumes that each document is a mixture of topics and each topic is a mixture of words, and estimates both simultaneously from the data. The output of a topic model is a set of topics — each represented as a probability distribution over the vocabulary — and a set of document-topic distributions showing how much each topic contributes to each document. Interpreting topics requires human judgement: the researcher must examine the top words for each topic and decide what theme they represent. Topic models are **exploratory** rather than confirmatory: they are most useful for generating hypotheses about the thematic structure of a corpus rather than for testing specific hypotheses. There are two main flavours: - **Unsupervised (unseeded) topic models**: The researcher specifies the number of topics *k*; the model finds *k* topics that best explain the corpus. The researcher must then interpret and label each topic. - **Supervised (seeded) topic models**: The researcher provides seed terms that anchor specific topics, guiding the model toward themes of interest. More appropriate when the researcher has specific thematic hypotheses. ## Network Analysis {-} 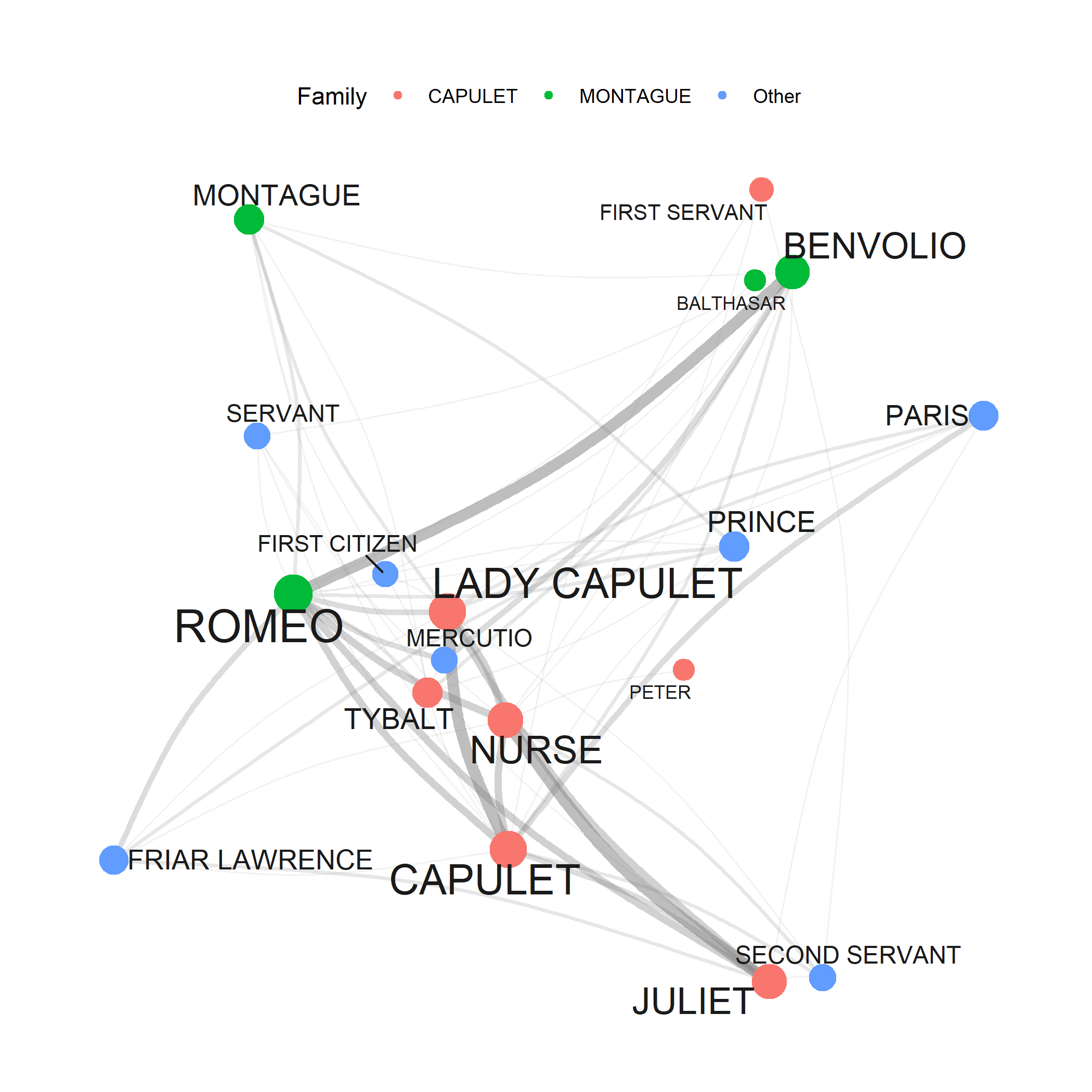{ width=40% style="float:right; padding:10px" } **Network Analysis** visualises and quantifies relationships between entities as graphs of nodes (entities) and edges (relationships). In text analysis, networks are used to represent co-occurrence relationships between words (collocation networks), interactions between characters in literary texts (character networks), citation relationships between academic papers, and communication networks derived from emails or social media. Key network metrics include **degree** (how many connections a node has), **betweenness centrality** (how often a node lies on the shortest path between other nodes — a measure of broker/bridge status), and **clustering coefficient** (how interconnected a node's neighbours are). Visualising networks reveals structural properties of relationships that tabular data cannot capture. ## Regular Expressions {-} **Regular expressions** (regex) are patterns of characters used to search, match, and manipulate text. A regular expression like `\b[Ww]alk\w*\b` matches any word beginning with *walk* or *Walk* — walk, walks, walked, walking, walker, Walk, Walks, etc. — regardless of where in the text it appears. Regular expressions are indispensable for text pre-processing (finding and replacing patterns), corpus searching (extracting examples matching complex criteria), and data cleaning. They are used in virtually every text analysis pipeline. A full introduction to regular expressions in R is available [here](/tutorials/regex/regex.html). ## Document Classification {-} **Document Classification** (also called text categorisation) is the process of assigning documents to predefined categories — genres, authors, languages, sentiment classes, topics, or any other labelling scheme. Classification can be: - **Rule-based**: Categories defined by explicit rules (e.g., documents containing the word *invoice* belong to the *financial* category) - **Feature-based machine learning**: Documents are represented as feature vectors (word frequencies, tf-idf weights, n-gram counts) and a classifier (logistic regression, SVM, random forest) is trained on labelled examples - **Deep learning**: Neural networks (LSTM, transformer models) that learn representations and classifications jointly from raw text Applications include authorship attribution, genre classification, spam filtering, language identification, and sentiment classification. --- ::: {.callout-tip} ## Exercises: Core Concepts ::: **Q1. A text contains 200 tokens but only 80 unique word forms. What is the type-token ratio, and what does it indicate?** ```{r}#| echo: false #| label: "CONC_Q1" check_question("TTR = 0.40 (80/200). A lower TTR indicates less lexical diversity — a smaller vocabulary relative to the total number of words used", options =c( "TTR = 0.40 (80/200). A lower TTR indicates less lexical diversity — a smaller vocabulary relative to the total number of words used", "TTR = 2.5 (200/80). A higher TTR indicates more lexical diversity", "TTR = 120 (200–80). This is the number of repeated words in the text", "TTR cannot be computed without knowing the lemmas of each word" ), type ="radio", q_id ="CONC_Q1", random_answer_order =TRUE, button_label ="Check answer", right ="Correct! TTR = types / tokens = 80 / 200 = 0.40. The ratio ranges from 0 to 1: a TTR of 1.0 means every token is a unique type (no repetition at all); a lower TTR means more repetition. A TTR of 0.40 is on the lower side, indicating that words are being reused frequently — typical of texts with a restricted vocabulary (children's books, legal boilerplate, highly technical texts). Note that TTR is sensitive to text length: longer texts tend to have lower TTRs because it becomes harder to avoid word repetition. Standardised measures like the Moving Average Type-Token Ratio (MATTR) control for this.", wrong ="TTR = types divided by tokens. With 80 types and 200 tokens, which direction does the division go, and what does a value below 1.0 mean for vocabulary diversity?") ```--- **Q2. What is the key conceptual difference between a COLLOCATION and a KEYWORD?** ```{r}#| echo: false #| label: "CONC_Q2" check_question("A collocation is a word that co-occurs with a specific target word more than expected by chance; a keyword is a word that is over-represented in one corpus compared to another (reference) corpus", options =c( "A collocation is a word that co-occurs with a specific target word more than expected by chance; a keyword is a word that is over-represented in one corpus compared to another (reference) corpus", "A collocation is always a two-word phrase; a keyword is always a single word", "Keywords are statistically significant; collocations are not", "Collocations are found in spoken corpora; keywords are found in written corpora" ), type ="radio", q_id ="CONC_Q2", random_answer_order =TRUE, button_label ="Check answer", right ="Correct! The key distinction is the baseline of comparison. Collocations are word-to-word: the question is whether two words co-occur more than would be expected given their individual frequencies in the corpus. The reference is the rest of the corpus. Keywords are corpus-to-corpus: the question is whether a word appears more frequently in the target corpus than in a separate reference corpus. Both use similar statistical machinery (contingency tables, association measures) but address different questions: collocations are about phraseological attraction; keywords are about what makes one text or corpus distinctive relative to another.", wrong ="Both collocations and keywords involve statistical comparison, but they compare different things. What is each compared against?") ```--- **Q3. A topic model of 500 news articles produces 10 topics. Topic 3 has the top words: *bank*, *loan*, *rate*, *interest*, *federal*, *mortgage*, *credit*, *reserve*. What is the appropriate next step?** ```{r}#| echo: false #| label: "CONC_Q3" check_question("A researcher inspects the word list and assigns an interpretive label (e.g., 'Financial/Monetary Policy'). This is the human interpretation step that the algorithm cannot perform.", options =c( "A researcher inspects the word list and assigns an interpretive label (e.g., 'Financial/Monetary Policy'). This is the human interpretation step that the algorithm cannot perform.", "The model automatically labels the topic as 'Finance' — no human input is needed", "The word list is validated by checking its p-value against a null hypothesis", "The analyst removes this topic because it is too obvious to be informative" ), type ="radio", q_id ="CONC_Q3", random_answer_order =TRUE, button_label ="Check answer", right ="Correct! The topic model produces word lists; it does not produce labels or meanings. A researcher must inspect each topic's top words and decide: (1) whether the co-occurring words form a coherent, interpretable theme; (2) what to name that theme; and (3) whether the theme is substantively interesting for the research question. This interpretive step is the human contribution that makes topic modelling a tool for research rather than just a statistical exercise. Topics that appear incoherent or dominated by function words often indicate that pre-processing choices (e.g., stopword removal) need revisiting.", wrong ="Topic models are unsupervised — they do not know what the topics mean, only that certain words co-occur. What does this mean for labelling?") ```--- # Data Sources for Text Analysis {#datasources} ::: {.callout-note} ## Section Overview **What you'll learn:** Where to find text data for analysis, what to look for when evaluating a data source, and how to access key resources ::: Text data is available from an enormous variety of sources, but not all data is equally suitable for all research purposes. The key questions when evaluating a data source are: Who produced these texts? For what purpose? When? What selection biases might be present? And under what conditions is the data available? ## Digitised Literary and Historical Archives {-} **Project Gutenberg** is the oldest digital library, containing over 60,000 ebooks in the public domain (free of US copyright). It is an excellent resource for literary, historical, and cultural text analysis. The `gutenbergr` R package provides direct access to the Project Gutenberg collection. A full tutorial on using `gutenbergr` is available [here](/tutorials/gutenberg/gutenberg.html). **HathiTrust Digital Library** contains over 17 million digitised volumes from major research libraries and is a major resource for large-scale literary and historical research. **Internet Archive** provides access to billions of web pages via the Wayback Machine, as well as digitised books, films, music, and other media. ## Linguistic Corpora {-} Purpose-built linguistic corpora are typically higher quality than opportunistically collected text data because they have explicit design criteria, metadata, and documentation. Major publicly accessible corpora include: - **COCA** (Corpus of Contemporary American English): 1 billion+ words, multiple genres, 1990–present - **BNC** (British National Corpus): 100 million words of late 20th-century British English - **CHILDES**: Child language acquisition data in dozens of languages - **ICE** (International Corpus of English): Comparable national varieties of English worldwide - **SketchEngine**: A corpus tool providing access to many large corpora ## News and Social Media {-} News archives (e.g., LexisNexis, Factiva, ProQuest) provide access to newspaper and magazine articles, though typically behind paywalls. The GDELT Project offers open access to media monitoring data at massive scale. Social media platforms (Twitter/X, Reddit, YouTube comments) have historically provided APIs for research access, though these have become significantly more restricted in recent years. Existing datasets curated under previous API conditions remain valuable resources. ## Government and Institutional Data {-} Parliamentary debates (Hansard in the UK, Congressional Record in the US), court judgements, government reports, and policy documents are typically in the public domain and available for research. These provide valuable data for political, legal, and historical research. ## Web Scraping {-} Web scraping — programmatically downloading and extracting text from websites — can provide access to text data not available through APIs or archives. Web scraping raises legal, ethical, and technical considerations: researchers should check robots.txt files, comply with terms of service, and avoid overloading servers. The `rvest` R package is the primary tool for web scraping in R. --- # Epistemological and Ethical Considerations {#epistemology} ::: {.callout-note} ## Section Overview **What you'll learn:** The limitations of computational text analysis, the epistemological claims it can and cannot support, and the ethical issues raised by working with text data **Why it matters:** Understanding what text analysis cannot do is as important as understanding what it can do ::: ## What Text Analysis Can and Cannot Do {-} Text analysis is a powerful set of methods, but it is not a magic box that produces truth from data. Several limitations deserve explicit acknowledgement: **Texts are not behaviour**: Most text data is not a random sample of linguistic behaviour — it is a selection shaped by who wrote, what they wrote about, who published it, and who preserved it. Literary corpora overrepresent canonical (and often Western, male, and elite) texts. Social media data overrepresents young, English-speaking, and technology-using populations. Historical corpora preserve official and literate production and lose oral, informal, and marginalised voices. **Frequencies are not meanings**: The fact that a word is frequent, or that two words co-occur, or that a topic appears in a corpus, does not tell us what these patterns *mean*. Meaning is always contextual, cultural, and interpretive — and assigning it to computational outputs requires the same careful scholarly judgement as any other form of textual interpretation. **Models embody assumptions**: Every text analysis method embeds assumptions about language, meaning, and text. A bag-of-words model assumes that word order does not matter. A topic model assumes that documents are mixtures of topics. A sentiment lexicon encodes one community's judgements about word valence. When these assumptions do not match the data or the research question, results can be misleading. **Criticism of Digital Humanities**: Text Analysis and computational literary studies have attracted criticism for producing results that are either "banal or, if interesting, not statistically robust" — findings that are either obvious or methodologically questionable. This criticism is not without merit: many early text analysis studies applied methods uncritically, without adequate statistical rigour or connection to theoretical frameworks. The field is maturing, and researchers coming from quantitative traditions (statistics, corpus linguistics) are increasingly contributing methodological rigour. But the obligation to evaluate whether computational findings are actually new, meaningful, and methodologically sound remains a live concern. ## Ethical Considerations {-} **Copyright and intellectual property**: Most texts produced after the early 20th century are under copyright, which restricts how they can be copied, distributed, and used. Research use of copyright material is governed by fair use / fair dealing provisions in different jurisdictions, but these are not unlimited. Researchers should understand the licensing terms of any data source they use. **Privacy and informed consent**: Texts produced in public contexts (newspaper articles, published books) are generally available for research. Texts produced in semi-public or private contexts — social media posts, forum contributions, emails — raise more complex questions. Individuals may not expect their words to be collected, analysed, and published, even if those words appeared in a publicly accessible space. **Bias and representation**: As noted above, text corpora are never neutral or representative. Computational analyses can amplify existing biases in the data, producing findings that reflect the composition of the corpus rather than anything true about the phenomena of interest. **Dual use**: Some text analysis methods — surveillance of online communication, automated profiling of individuals, large-scale opinion monitoring — can be used in ways that raise serious concerns about privacy, civil liberties, and the instrumentalisation of language research. --- # Tools versus Scripts: The Case for Reproducible Research {#tools} ::: {.callout-note} ## Section Overview **What you'll learn:** Why code-based, script-driven text analysis is preferable to point-and-click tools for research purposes **Key principle:** Reproducibility is not just a technical nicety — it is a scientific and ethical obligation ::: It is entirely possible to perform many text analysis tasks using graphical tools like [AntConc](https://www.laurenceanthony.net/software/antconc/)[@anthony2024antconc] or [SketchEngine](https://www.sketchengine.eu/)[@kilgarriff2014sketch]. These tools are user-friendly, powerful, and appropriate for many purposes. So why does LADAL recommend script-based analysis in R? **Reproducibility**: When analysis is performed by clicking through a graphical interface, there is no automatic record of what was done. Replicating the analysis requires redoing every step manually. When analysis is performed in an R script, every step is recorded, can be rerun with one command, and can be shared with other researchers. **Transparency**: Scripts make the full analytical workflow visible — every pre-processing decision, every parameter setting, every statistical test. Point-and-click tools often obscure these decisions, making it difficult for readers to evaluate the methodological choices. **Flexibility and power**: Graphical tools implement a fixed set of analyses. R provides access to hundreds of packages covering the full range of text analysis methods, which can be combined in arbitrary ways to address novel research questions. **Scalability**: Running the same analysis on 100 files in R takes the same code as running it on 1 file. Doing the same in a GUI requires 100 repetitions of the same manual steps. **No vendor lock-in**: Commercial tools (SketchEngine, NVivo) can change their pricing, APIs, or feature sets. Open source R packages remain available indefinitely and can be archived along with data and analysis code to ensure long-term reproducibility. **Community and error correction**: R is one of the most widely used languages for statistical computing globally. A large, active community means that errors in packages are typically discovered and corrected quickly, documentation is extensive, and help is readily available. None of this means that GUI tools have no place in research. They are valuable for exploratory work, teaching, and contexts where reproducibility requirements are lower. But for published research that claims to support generalisable conclusions, script-based analysis is the appropriate standard. --- ::: {.callout-tip} ## Exercises: Epistemology and Tools ::: **Q1. A researcher analyses 10,000 tweets from 2020 about the US presidential election and concludes that "American voters were more excited about Biden than Trump." What is the most significant methodological problem with this conclusion?** ```{r}#| echo: false #| label: "EPIS_Q1" check_question("Twitter users are not representative of American voters — they skew younger, more educated, and more politically engaged; the corpus reflects Twitter's user population, not the electorate", options =c( "Twitter users are not representative of American voters — they skew younger, more educated, and more politically engaged; the corpus reflects Twitter's user population, not the electorate", "The sample of 10,000 tweets is too small for statistical analysis", "Tweet text cannot be analysed computationally because it contains too much slang", "The researcher should have used Facebook data instead" ), type ="radio", q_id ="EPIS_Q1", random_answer_order =TRUE, button_label ="Check answer", right ="Correct! This is a corpus representativeness problem. The conclusion is about 'American voters' but the data is from Twitter users — a non-representative sample. Twitter's user base is systematically different from the general population in age, education, income, and political engagement. Frequency patterns in a Twitter corpus reflect who is on Twitter and how they use it, not what American voters in general think or feel. This is an extremely common error in social media text analysis: conflating patterns in the available data with claims about the broader population.", wrong ="The sample size is not the core problem — 10,000 tweets is actually substantial. The issue is about who the tweets are from and whether they represent the population described in the conclusion.") ```--- **Q2. A PhD student performs keyword analysis by clicking through a commercial text analysis tool, finds significant keywords, and writes up the results. A reviewer asks: 'What stopword list did you use? How was the reference corpus constructed?' Why can the student not easily answer these questions?** ```{r}#| echo: false #| label: "EPIS_Q2" check_question("GUI tools often apply default settings (stopword lists, reference corpora) without explicitly showing or recording them; without a script, the exact analytical choices are not documented and may not be discoverable", options =c( "GUI tools often apply default settings (stopword lists, reference corpora) without explicitly showing or recording them; without a script, the exact analytical choices are not documented and may not be discoverable", "The student should have used a larger reference corpus", "Keyword analysis does not use stopword lists", "Reviewers cannot ask methodological questions about computational text analysis" ), type ="radio", q_id ="EPIS_Q2", random_answer_order =TRUE, button_label ="Check answer", right ="Correct! This illustrates the transparency and reproducibility problem with GUI-based analysis. Commercial and even open-source GUI tools apply default settings (stopword lists, tokenisation rules, reference corpus selection) that are not always displayed or documented in the interface. Without a script recording every step, the researcher may not know — let alone be able to tell a reviewer — exactly what decisions were made. An R script would make every such decision explicit and replicable. This is not a hypothetical concern: methodological variation in 'default' settings can have substantial effects on results.", wrong ="Think about what a GUI hides from the researcher versus what a script exposes.") ```--- # Resources and Further Reading {#resources} ## LADAL Tutorials {-} LADAL provides tutorials covering the practical implementation of all the methods described in this tutorial: - [Part 2: Practical Text Analysis in R](/tutorials/textanalysis/textanalysis2.html) — implementation of concordancing, frequency analysis, collocation analysis, keyword analysis, and more - [Concordancing (KWIC)](/tutorials/concordancing_tutorial/concordancing_tutorial.html)- [String Processing in R](/tutorials/string/string.html)- [Regular Expressions in R](/tutorials/regex/regex.html)- [Collocation Analysis in R](/tutorials/coll/coll.html)- [Keyword Analysis in R](/tutorials/keywords/keywords.html)- [Sentiment Analysis in R](/tutorials/sentiment/sentiment.html)- [Topic Modelling in R](/tutorials/topicmodels/topicmodels.html)## Text Analysis at UQ {-} The [UQ Library](https://www.library.uq.edu.au/) provides an excellent summary of [resources, concepts, and tools](https://guides.library.uq.edu.au/research-techniques/text-mining-analysis/introduction) for Text Analysis and Distant Reading, including video introductions and coverage of [copyright issues](https://guides.library.uq.edu.au/research-techniques/text-mining-analysis/considerations), [data sources](https://guides.library.uq.edu.au/research-techniques/text-mining-analysis/sources-of-text-data), and [web scraping](https://guides.library.uq.edu.au/research-techniques/text-mining-analysis/web-scraping). ## Key References {-} Key works for deeper engagement with Text Analysis theory and methods include @welbers2017text, @jockers2020text, @moretti2013distant, @sinclair1991corpus, @eisenstein2019introduction, and @silge2017text. # Citation & Session Info {-} ::: {.callout-note}## Citation```{r citation-callout, echo=FALSE, results='asis'}cat( params$author, ". ", params$year, ". *", params$title, "*. ", params$institution, ". ", "url: ", params$url, " ", "(Version ", params$version, "), ", "doi: ", params$doi, ".", sep = "")``````{r citation-bibtex, echo=FALSE, results='asis'}key <- paste0( tolower(gsub(" ", "", gsub(",.*", "", params$author))), params$year, tolower(gsub("[^a-zA-Z]", "", strsplit(params$title, " ")[[1]][1])))cat("```\n")cat("@manual{", key, ",\n", sep = "")cat(" author = {", params$author, "},\n", sep = "")cat(" title = {", params$title, "},\n", sep = "")cat(" year = {", params$year, "},\n", sep = "")cat(" note = {", params$url, "},\n", sep = "")cat(" organization = {", params$institution, "},\n", sep = "")cat(" edition = {", params$version, "}\n", sep = "")cat(" doi = {", params$doi, "}\n", sep = "")cat("}\n```\n")```:::```{r fin} sessionInfo() ```::: {.callout-note}## AI Transparency StatementThis tutorial was developed with the assistance of **Claude** (claude.ai), a large language model created by Anthropic. Claude was used to help draft the tutorial text, structure the instructional content, generate the R code examples, and write the `checkdown` quiz questions and feedback strings. All content was reviewed, edited, and approved by the author (Martin Schweinberger), who takes full responsibility for the accuracy and pedagogical appropriateness of the material. The use of AI assistance is disclosed here in the interest of transparency and in accordance with emerging best practices for AI-assisted academic content creation.:::[Back to top](#intro)[Back to HOME](/index.html)